Ensuring Reliability in Neuroimaging Pipelines: A Framework for Reproducible Research and Drug Development
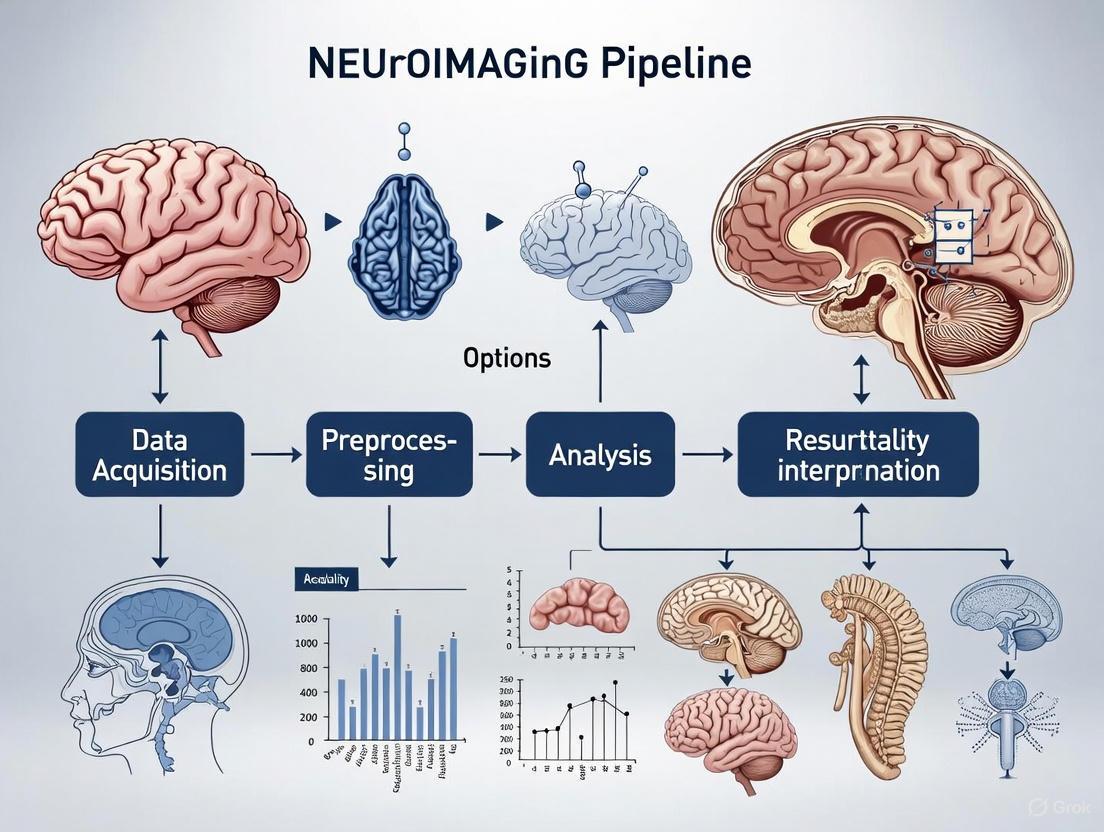
This article addresses the critical challenge of reliability and reproducibility in neuroimaging pipelines, a central concern for researchers and drug development professionals.
Ensuring Reliability in Neuroimaging Pipelines: A Framework for Reproducible Research and Drug Development
Abstract
This article addresses the critical challenge of reliability and reproducibility in neuroimaging pipelines, a central concern for researchers and drug development professionals. It explores the foundational sources of methodological variability introduced by software, parcellation, and quality control choices, demonstrating their significant impact on both group-level inference and individual prediction tasks. The content evaluates next-generation, deep learning-based pipelines that offer substantial acceleration and enhanced robustness for large-scale datasets and clinical applications. Furthermore, it provides a rigorous framework for reliability assessment and validation, covering standardized metrics, comparative performance evaluation, and optimization strategies for troubleshooting pipeline failures. By synthesizing evidence from recent large-scale comparative studies and emerging technologies, this guide aims to equip scientists with practical knowledge to design robust, efficient, and reliable neuroimaging workflows for both research and clinical trial contexts.
The Reproducibility Crisis: Understanding Sources of Variability in Neuroimaging Analysis
FAQs: Core Concepts for Pipeline Reliability
Q1: What is the fundamental difference between replicability and generalizability in a neuroimaging context?
Replicability refers to obtaining consistent results when repeating an experiment or analysis under the same or very similar conditions (e.g., the same lab, scanner, and participant population). Generalizability, or external validity, refers to the ability of a result to apply to a different but related context, such as a novel sample from a different population, a different data acquisition site, or a different scanner model [1].
Q2: Why are large sample sizes increasingly emphasized for population neuroscience studies?
Brain-behavior associations, particularly in psychiatry, typically have very small effect sizes (e.g., maximum correlations of ~0.10 between brain connectivity and mental health symptoms) [2]. Small samples (e.g., tens to hundreds of participants) exhibit high sampling variability, leading to inflated effect sizes, false positives, and ultimately, replication failures. Samples in the thousands are required to achieve the statistical power necessary for replicable and accurate effect size estimation [2] [3].
Q3: How can my pipeline be replicable but not generalizable?
A pipeline can produce highly consistent results within a specific, controlled dataset but fail when applied elsewhere. This often occurs due to "shortcut learning," where a machine learning model learns an association between the brain and an unmeasured, dataset-specific construct (the "shortcut") rather than the intended target of mental health [2] [3]. For example, a model might leverage site-specific scanner artifacts for prediction, which do not transfer to other sites.
Q4: What technological solutions can enhance the trustworthiness of my pipeline's output?
Cyberinfrastructure solutions like the Open Science Chain (OSC) can be integrated. The OSC uses consortium blockchain to maintain immutable, timestamped, and verifiable integrity and provenance metadata for published datasets and workflow artifacts. Storing cryptographic hashes of data and metadata in this "append-only" ledger allows for independent verification, fostering trust and promoting reuse [4].
Troubleshooting Guide: Common Pipeline Issues and Solutions
Issue: Inconsistent Functional Connectomics Results Across Research Groups
- Problem: Different groups analyzing the same data obtain different conclusions about brain network organization.
- Diagnosis: This is a classic problem of combinatorial pipeline variability. A single choice in node definition, edge weighting, or global signal processing can drastically alter results [5].
- Solution:
- Systematic Evaluation: Systematically evaluate your pipeline choices against multiple criteria. Do not optimize for a single metric.
- Adopt Verified Pipelines: Use pipelines that have been validated against key criteria. A systematic evaluation of 768 pipelines identified optimal ones that minimize motion confounds and spurious test-retest discrepancies while remaining sensitive to inter-subject differences and experimental effects [5]. Key performance criteria are summarized in Table 1 below.
- Be Transparent: Fully report all pipeline choices, including parcellation, connectivity metric, and global signal regression usage.
Issue: fMRIPrep Crashes with 'Operation not permitted' Error on a Compute Cluster
- Problem: fMRIPrep runs successfully manually but crashes with
shutil.Errorand[Errno 1] Operation not permittedwhen executed through a cluster management system, specifically when copying the 'fsaverage' files [6]. - Diagnosis: This is likely a file permissions incompatibility arising from the interaction between the Singularity container, the cluster's architecture, and how the pipeline is invoked. The system may be setting up data with a user ID that is not compatible with the container's operations.
- Solution:
- Investigate the
-uUID Option: Although you may not be using it, the underlying issue is related to user ID mapping. Deliberately using the-uoption with Singularity to set a specific user ID (e.g.,-u 0for root) may resolve the permission conflict [6]. - Pre-copy fsaverage: As a workaround, try copying the
fsaveragedirectory from inside the container to your target output directory before running fMRIPrep, ensuring it has full read/write permissions.
- Investigate the
Quantitative Data on Pipeline Performance
Table 1: Performance Criteria for Evaluating fMRI Processing Pipelines for Functional Connectomics [5]
| Criterion | Description | Why It Matters |
|---|---|---|
| Test-Retest Reliability | Minimizes spurious differences in network topology from repeated scans of the same individual. | Fundamental for studying individual differences. Unreliable pipelines produce misleading associations with traits or clinical outcomes. |
| Motion Robustness | Minimizes the confounding influence of head motion on network topology. | Prevents false findings driven by motion artifacts rather than neural signals. |
| Sensitivity to Individual Differences | Able to detect consistent, unique network features that distinguish one individual from another. | Essential for personalized medicine or biomarker discovery. |
| Sensitivity to Experimental Effects | Able to detect changes in network topology due to a controlled intervention (e.g., pharmacological challenge). | Ensures the pipeline can capture biologically relevant, stimulus-driven changes in brain function. |
| Generalizability | Performs consistently well across multiple independent datasets with different acquisition parameters and preprocessing methods. | Protects against overfitting to a specific dataset's properties and ensures broader scientific utility. |
Table 2: Benchmark Effect Sizes in Population Psychiatric Neuroimaging [2]
| Brain-Behavior Relationship | Dataset | Sample Size (N) | Observed Maximum Correlation (r) |
|---|---|---|---|
| Resting-State Functional Connectivity (RSFC) vs. Fluid Intelligence | Human Connectome Project (HCP) | 900 | ~0.21 |
| RSFC vs. Fluid Intelligence | Adolescent Brain Cognitive Development (ABCD) Study | 3,928 | ~0.12 |
| RSFC vs. Fluid Intelligence | UK Biobank (UKB) | 32,725 | ~0.07 |
| Brain Measures vs. Mental Health Symptoms | ABCD Study | 3,928 | ~0.10 |
Experimental Protocols for Reliability Assessment
This protocol outlines a two-step process for translating a neuroimaging finding from the lab toward clinical application.
Replication Experiments:
- Objective: To measure the precision of a finding when the experiment is repeated as precisely as possible.
- Method: Perform test-retest measurements on the same or a highly matched population, using the same data acquisition instruments (e.g., the same scanner and sequence) and the same computational pipeline.
- Outcome Measurement: Quantify the intra-class correlation (ICC) or other reliability metrics for the key output measures (e.g., fractional anisotropy, network metric).
Generalization Experiments:
- Objective: To test the extent of applicability of the replicated finding.
- Method: Conduct experiments that share the same core design but systematically vary one or more parameters:
- Population: Test on participants from different geographic locales, age groups, or clinical backgrounds.
- Data Acquisition: Use different scanner models, manufacturers, or pulse sequences.
- Computational Methods: Apply different preprocessing software or algorithmic parameters.
- Outcome Measurement: Assess how the key output measure and its reliability change across these varying conditions.
This protocol describes a comprehensive method for identifying optimal pipelines for functional connectomics.
Define the Pipeline Variable Space: Systematically combine choices across key steps:
- Global Signal Regression: With or without.
- Brain Parcellation: Use 4 different types (anatomical, functional, etc.) at 3 different resolutions (~100, 200, 300-400 nodes).
- Edge Definition: Use Pearson correlation or mutual information.
- Edge Filtering: Apply 8 different methods (e.g., density-based thresholding, data-driven methods).
- Network Type: Binary or weighted.
- This creates 768 unique, end-to-end pipelines for evaluation.
Evaluate on Multiple Independent Datasets: Run the evaluation on at least two independent test-retest datasets, spanning different time delays (e.g., minutes, weeks, months).
Apply Multi-Criteria Assessment: Evaluate each pipeline against the criteria listed in Table 1, using a robust metric like Portrait Divergence (PDiv) that compares whole-network topology.
Identify Optimal Pipelines: Select pipelines that satisfy all criteria (high test-retest reliability, motion robustness, and sensitivity to effects of interest) across all datasets.
Experimental Workflow and Signaling Diagrams
Diagram: Two-Step Framework for Reliability Assessment
Diagram: Combinatorial Explosion in fMRI Pipeline Construction
The Scientist's Toolkit: Key Research Reagents & Materials
Table 3: Essential Resources for Neuroimaging Pipeline Research
| Resource / Reagent | Type | Primary Function / Relevance |
|---|---|---|
| Open Science Chain (OSC) [4] | Cyberinfrastructure Platform | Provides a blockchain-based platform to immutably store cryptographic hashes of data and metadata, ensuring integrity and enabling independent verification of research artifacts. |
| fMRIPrep [6] | Software Pipeline | A robust, standardized tool for preprocessing of fMRI data, helping to mitigate variability introduced at the initial data cleaning stages. |
| Human Connectome Project (HCP) Data [2] [5] | Reference Dataset | A high-quality, publicly available dataset acquired with advanced protocols, often used as a benchmark for testing pipeline performance and generalizability. |
| Adolescent Brain Cognitive Development (ABCD) Study Data [2] | Reference Dataset | A large-scale, longitudinal dataset with thousands of participants, essential for benchmarking effect sizes and testing pipelines on large, diverse samples. |
| UK Biobank (UKB) Data [2] | Reference Dataset | A very large-scale dataset from a general population, crucial for obtaining accurate estimates of small effect sizes and stress-testing pipeline generalizability. |
| Portrait Divergence (PDiv) [5] | Analysis Metric | An information-theoretic measure for quantifying the dissimilarity between whole-network topologies, used for evaluating test-retest reliability and sensitivity. |
Frequently Asked Questions (FAQs)
Software and Pipeline Selection
Q: What are the most common sources of analytical variability in fMRI studies? A: The primary sources include: 1) Choice of software package (SPM, FSL, AFNI); 2) Processing parameters such as spatial smoothing kernel size; 3) Modeling choices like HRF modeling and motion regressor inclusion; 4) Brain parcellation schemes for defining network nodes; and 5) Quality control procedures. One study found that across 70 teams analyzing the same data, results varied significantly due to these analytical choices [7] [8].
Q: Which fMRI meta-analysis software packages are most widely used? A: A 2025 survey of 820 papers found the following usage prevalence [9]:
Table: fMRI Meta-Analysis Software Usage (2019-2024)
| Software Package | Number of Papers | Percentage |
|---|---|---|
| GingerALE | 407 | 49.6% |
| SDM-PSI | 225 | 27.4% |
| Neurosynth | 90 | 11.0% |
| Other | 131 | 16.0% |
Q: How does parcellation choice affect network analysis results? A: Parcellation selection significantly impacts derived network topology. Systematic evaluations reveal that the definition of network nodes (from discrete anatomically-defined regions to continuous, overlapping maps) creates vast variability in network organization and subsequent conclusions about brain function. Inappropriate parcellation choices can produce misleading results that are systematically biased rather than randomly distributed [5].
Quality Control and Error Management
Q: What are the best practices for quality control of automated brain parcellations? A: EAGLE-I (ENIGMA's Advanced Guide for Parcellation Error Identification) provides a systematic framework for visual QC. It classifies errors by: 1) Type (unconnected vs. connected); 2) Size (minor, intermediate, major); and 3) Directionality (overestimation vs. underestimation). Manual QC remains the gold standard, though automated alternatives using Euler numbers or MRIQC scores provide time-efficient alternatives [10] [11].
Q: How prevalent are parcellation errors in neuroimaging studies? A: Parcellation errors are common even in high-quality images without pathology. In clinical populations with conditions like traumatic brain injury, these errors are exacerbated by focal pathology affecting cortical regions. Despite this, many published studies using automated parcellation tools do not specify whether quality control was performed [10].
Troubleshooting Guides
Pipeline Inconsistencies
Problem: Inconsistent results across research groups using the same dataset. Solution:
- Systematic pipeline documentation: Use standardized descriptors for pipelines (e.g., "software-FWHM-number of motion regressors-presence of HRF derivatives") [7]
- Containerization: Implement Docker/NeuroDocker images to fix software versions and environments [7] [8]
- Multi-pipeline evaluation: Test analysis robustness across multiple pipeline permutations rather than relying on a single pipeline
- Provenance tracking: Use platforms like NeuroAnalyst to maintain complete records of data transformations [12]
Parcellation Errors
Problem: Automated parcellation tools (FreeSurfer, FastSurfer) produce errors in brain region boundaries. Troubleshooting Steps:
- Systematic visual inspection: Load parcellation images and inspect each region sequentially [10]
- Error classification: Categorize errors by type, size, and directionality using standardized criteria
- Threshold determination: Establish clear thresholds for when errors warrant exclusion
- Use EAGLE-I error tracker: Utilize the standardized spreadsheet for consistent error recording [10]
Functional Connectivity Variability
Problem: Inconsistent functional network topologies from the same resting-state fMRI data. Solution Protocol:
- Systematic pipeline evaluation: Test combinations of parcellation, connectivity definition, and global signal processing [5]
- Multi-criterion validation: Assess pipelines based on motion robustness, test-retest reliability, and biological sensitivity
- Topological consistency: Use portrait divergence (PDiv) to measure network dissimilarity across all organizational scales
- Optimal pipeline selection: Identify pipelines satisfying reliability criteria across multiple datasets and time intervals
Experimental Protocols
Protocol 1: Multi-Pipeline fMRI Analysis
Objective: To quantify analytical variability across different processing pipelines [7]
Materials:
- Raw fMRI data (e.g., HCP Young Adult dataset)
- Multiple software packages (SPM, FSL)
- High-performance computing environment
- Containerization platform (Docker/NeuroDocker)
Methodology:
- Select varying parameters:
- Software package (SPM12, FSL 6.0.3)
- Spatial smoothing (FWHM: 5mm, 8mm)
- Motion regressors (0, 6, or 24 parameters)
- HRF modeling (with/without derivatives)
Implement pipelines using workflow tools (Nipype 1.6.0)
Process all subjects through each pipeline permutation (e.g., 24 pipelines)
Extract statistical maps for individual and group-level analyses
Compare results across pipelines using spatial similarity metrics
Protocol 2: Analytical Flexibility Assessment
Objective: To evaluate how analytical choices affect research conclusions [13]
Materials:
- Standardized dataset (e.g., FRESH fNIRS data, NARPS fMRI data)
- Multiple research teams (30+ groups)
- Hypothesis testing framework
- Results collation system
Methodology:
- Provide identical datasets to multiple analysis teams
Define specific hypotheses with varying literature support
Allow independent analysis using teams' preferred pipelines
Collect results using standardized reporting forms
Quantify agreement across teams for each hypothesis
Identify pipeline features associated with divergent conclusions
Research Reagent Solutions
Table: Essential Tools for Neuroimaging Reliability Research
| Tool/Category | Specific Examples | Function/Purpose |
|---|---|---|
| Analysis Software | SPM12, FSL 6.0.3, AFNI | Statistical analysis of neuroimaging data |
| Meta-Analysis Tools | GingerALE 2.3.6+, SDM-PSI 6.22, NiMARE | Coordinate-based and image-based meta-analysis |
| Pipelines & Workflows | HCP Multi-Pipeline, NARPS pipelines | Standardized processing streams for reproducibility |
| Containerization | NeuroDocker, Neurodesk | Environment consistency across computational platforms |
| Quality Control | EAGLE-I, MRIQC, Qoala-T | Identification and classification of processing errors |
| Data Provenance | NeuroAnalyst, OpenNeuro | Tracking data transformations and ensuring reproducibility |
| Parcellation Tools | FreeSurfer 6.0, FastSurfer | Automated brain segmentation and region definition |
The Impact of Preprocessing Choices on Cortical Thickness Measures and Group Differences
Troubleshooting Guides and FAQs
Frequently Asked Questions
Q1: Why do my cortical thickness results change drastically when I use different software tools?
Software tools (e.g., FreeSurfer, ANTS, CIVET) employ different algorithms for image normalization, registration, and segmentation, leading to systematic variability in cortical thickness measurements. Studies show software selection significantly affects both group-level neurobiological inference and individual-level prediction tasks. For instance, even different versions of the same software (FreeSurfer 5.1, 5.3, 6.0) can produce varying results due to algorithmic improvements and parameter changes [14].
Q2: Should I use cortical thickness or volume-based measures for Alzheimer's disease research?
Cortical thickness measures are generally recommended over volume-based measures for studying age-related changes or sex effects across large age ranges. While both perform similarly for diagnostic separation, volume-based measures are highly correlated with head size (a nuisance covariate), while thickness-based measures generally are not. Volume-based measures require statistical correction for head size, and the approach to this correction varies across studies, potentially introducing inconsistencies [15].
Q3: What are the most common errors in automated cortical parcellation, and how can I identify them?
Common parcellation errors include unconnected errors (affecting a single ROI) and connected errors (affecting multiple ROIs), which can be further classified by size (minor, intermediate, major) and directionality (overestimation or underestimation). These errors are particularly prevalent in clinical populations with pathological features. Use systematic QC protocols like EAGLE-I that provide clear visual examples and classification criteria to identify errors by type, size, and direction [10].
Q4: How does quality control procedure selection impact my cortical thickness analysis results?
Quality control procedures significantly affect task-driven neurobiological inference and individual-centric prediction tasks. The stringency of QC (e.g., no QC, lenient manual, stringent manual, automatic outlier detection) directly influences which subjects are included in analysis, potentially altering study conclusions. Inconsistent QC application across studies contributes to difficulties in replicating findings [14].
Q5: My FreeSurfer recon-all finished without errors, but the surfaces look wrong. What should I do?
Recon-all completion doesn't guarantee anatomical accuracy. Common issues include skull strip errors, segmentation errors, intensity normalization errors, pial surface misplacement, and topological defects. Use FreeView to visually inspect whether surfaces follow gray matter/white matter borders and whether subcortical segmentation follows intensity boundaries. Manual editing may be required to correct these issues [16].
Troubleshooting Common Issues
Problem: Inaccurate Pial Surface Placement Symptoms: Red pial surfaces in FreeView appearing too deep or superficial relative to actual gray matter/CSF boundary. Solution: Edit the brainmask.mgz volume using FreeView to erase, fill, or clone voxels, then regenerate surfaces [16].
Problem: White Matter Segmentation Errors Symptoms: Holes in the wm.mgz volume visible in FreeView, often corresponding to surface dimples or inaccuracies. Solution: Manually edit the wm.mgz volume to fill segmentation gaps, ensuring continuous white matter representation [16].
Problem: Topological Defects Symptoms: Small surface tears or inaccuracies, particularly in posterior brain regions, often visible only upon close inspection. Solution: Use FreeSurfer's topological defect correction tools to identify and repair surface inaccuracies [16].
Problem: Skull Stripping Failures Symptoms: Brainmask.mgz includes non-brain tissue or excludes parts of cortex/cerebellum when compared to original T1.mgz. Solution: Manually edit brainmask.mgz to include excluded brain tissue or remove non-brain tissue, then reprocess [16].
Table 1: Impact of Preprocessing Choices on Cortical Thickness Analysis
| Preprocessing Factor | Impact Level | Specific Effects | Recommendations |
|---|---|---|---|
| Software Tool [14] | High | • Significant effect on group-level and individual-level analyses• Different versions (FS 5.1, 5.3, 6.0) yield different results | • Consistent version use within study• Cross-software validation for critical findings |
| Parcellation Atlas [14] | Medium-High | • DKT, Destrieux, Glasser atlases produce varying thickness measures• Different anatomical boundaries and region definitions | • Atlas selection based on research question• Consistency across study participants |
| Quality Control [14] | High | • QC stringency affects sample size and results• Manual vs. automatic QC yield different subject inclusions | • Pre-specify QC protocol• Report QC criteria and exclusion rates |
| Global Signal Regression [5] | Context-Dependent | • Controversial preprocessing step for functional data• Systematically alters network topology | • Pipeline-specific recommendations• Consistent application across dataset |
| Metric | Diagnostic Separation | Head Size Correlation | Test-Retest Reliability | Clinical Correlation |
|---|---|---|---|---|
| Cortical Thickness | Comparable to volume measures | Generally not correlated | Lower than volume measures | Correlates with Braak NFT stage |
| Volume Measures | Comparable to thickness measures | Highly correlated | Higher than thickness measures | Correlates with Braak NFT stage |
Experimental Protocols
Objective: Evaluate the impact of preprocessing pipelines on cortical thickness measures using open structural MRI datasets.
Materials:
- ABIDE dataset (573 controls, 539 ASD individuals from 16 international sites)
- Human Connectome Project validation data
- Processing tools: ANTS, CIVET, FreeSurfer (versions 5.1, 5.3, 6.0)
- Parcellations: Desikan-Killiany-Tourville, Destrieux, Glasser
- Quality control procedures: No QC, manual lenient, manual stringent, automatic low/high-dimensional
Methodology:
- Process structural MRI data through multiple pipeline combinations (5 software × 3 parcellations × 5 QC)
- Extract cortical thickness measures for each pipeline variation
- Perform statistical analyses divided by method type (task-free vs. task-driven) and inference objective (neurobiological group differences vs. individual prediction)
- Compare effect sizes and significance levels across pipelines
- Validate findings on independent HCP dataset
Objective: Systematically evaluate test-retest reliability and predictive validity of cortical thickness measures.
Materials:
- Multiple public datasets with repeated scans
- PhiPipe multimodal processing pipeline
- Comparison pipelines: DPARSF, PANDA
Methodology:
- Process T1-weighted images through multiple pipelines
- Calculate intra-class correlations (ICC) for test-retest reliability across four datasets
- Assess predictive validity by computing correlation between brain features and chronological age in three adult lifespan datasets
- Evaluate multivariate reliability and predictive validity
- Compare pipeline performance using standardized metrics
Workflow Diagrams
Cortical Thickness Pipeline Variability
Quality Control Decision Framework
Research Reagent Solutions
Table 3: Essential Tools for Cortical Thickness Analysis
| Tool/Resource | Type | Primary Function | Application Notes |
|---|---|---|---|
| FreeSurfer [14] [16] | Software Package | Automated cortical surface reconstruction and thickness measurement | Multiple versions (5.1, 5.3, 6.0) yield different results; recon-all requires visual QC |
| ANTS [14] [15] | Software Package | Advanced normalization tools for image registration | Recommended for AD signature measures with SPM12 segmentations |
| CIVET [14] | Software Package | Automated processing pipeline for structural MRI | Alternative to FreeSurfer with different algorithmic approaches |
| EAGLE-I [10] | QC Protocol | Standardized parcellation error identification and classification | Reduces inter-rater variability; provides clear error size thresholds |
| PhiPipe [17] | Multimodal Pipeline | Processing for T1-weighted, resting-state BOLD, and DWI MRI | Generates atlas-based brain features with reliability/validity metrics |
| fMRIPrep [18] [19] | Preprocessing Tool | Robust fMRI preprocessing pipeline | Requires quality control of input images; sensitive to memory issues |
| BIDS Standard [19] | Data Structure | Consistent organization of neuroimaging data and metadata | Facilitates reproducibility and pipeline standardization across studies |
The reliability of neuroimaging findings in Autism Spectrum Disorder (ASD) research is fundamentally tied to the data processing pipelines selected by investigators. This technical support center document examines how pipeline selection influences findings derived from the Autism Brain Imaging Data Exchange (ABIDE) dataset, a large-scale multi-site repository containing over 1,000 resting-state fMRI datasets from individuals with ASD and typical controls [20]. We provide troubleshooting guidance, methodological protocols, and analytical frameworks to help researchers navigate pipeline-related challenges and enhance the reproducibility of their neuroimaging findings.
Troubleshooting Guides
Problem 1: Inconsistent Classification Accuracy Across Sites
Issue: Machine learning models show significantly reduced accuracy when applied across different imaging sites compared to within-site performance.
Background: Multi-site data aggregation increases sample size but introduces scanner-induced technical variability that can mask true neural effects [21]. One study reported classification accuracy dropped substantially in leave-site-out validation compared to within-site performance [21].
Solutions:
- Implement Data Harmonization: Use ComBat harmonization to remove site-specific effects while preserving biological signals [21]. This technique employs empirical Bayes formulation to adjust for inter-site differences in data distributions.
- Cross-Validation Strategy: Adopt leave-site-out cross-validation where models are trained on data from all but one site and tested on the held-out site [21].
- Site Covariates: Include site as a covariate in statistical models when harmonization isn't feasible.
Problem 2: Head Motion Artifacts
Issue: Head movement during scanning introduces spurious correlations in functional connectivity measures.
Background: Even small head movements (mean framewise displacement >0.2mm) can significantly impact functional connectivity estimates [22].
Solutions:
- Apply Motion Filtering: Implement rigorous motion filtering (e.g., excluding volumes with FD >0.2mm) [22]. One study demonstrated this increased classification accuracy from 91% to 98.2% [22].
- Include Motion Parameters: Regress out 24 motion parameters obtained during realignment in preprocessing [23].
- Motion as Covariate: Include mean framewise displacement as a nuisance covariate in group-level analyses.
Problem 3: Low Classification Accuracy with Structural MRI
Issue: Structural T1-weighted images yield poor classification accuracy (~60%) for ASD identification.
Background: Early studies using volumetric features achieved limited success, potentially due to focusing on scalar estimates rather than shape information [24].
Solutions:
- Leverage Surface-Based Morphometry: Implement surface-based features that capture intrinsic geometry, such as multivariate morphometry statistics combining radial distance and tensor-based morphometry [24].
- Apply Sparse Coding: Use patch-based surface sparse coding and dictionary learning to reduce high-dimensional shape descriptors [24]. This approach achieved >80% accuracy using hippocampal surface features.
- Max-Pooling: Incorporate max-pooling operations after sparse coding to summarize feature representations [24].
Problem 4: Non-Reproducible Biomarkers
Issue: Identified neural biomarkers fail to replicate across studies or datasets.
Background: Small sample sizes, cohort heterogeneity, and pipeline variability contribute to non-reproducible associations [25].
Solutions:
- Prioritize Reproducibility in Model Selection: Use criteria that quantify association reproducibility alongside predictive performance during model selection [25].
- Regularized Linear Models: Employ regularized generalized linear models with reproducibility-focused validation rather than models selected purely for predictive accuracy [25].
- Independent Validation: Always validate biomarkers on held-out datasets not used during model development [23].
Frequently Asked Questions
Q: Which machine learning approach yields the highest ASD classification accuracy on ABIDE data?
A: Current evidence suggests deep learning approaches with proper preprocessing achieve the highest performance. One study using a Stacked Sparse Autoencoder with functional connectivity data and rigorous motion filtering (FD >0.2mm) reached 98.2% accuracy [22]. However, reproducibility should be prioritized over maximal accuracy for biomarker discovery [25].
Q: What is the recommended sample size for achieving reproducible ASD biomarkers?
A: While no definitive minimum exists, studies achieving reproducible associations typically use hundreds of participants. The ABIDE dataset provides 1,112 datasets across 17 sites [20], and studies leveraging this resource with appropriate harmonization have found more consistent results [21] [23].
Q: How can I determine whether my pipeline is capturing neural signals versus dataset-specific artifacts?
A: Implement the Remove And Retrain (ROAR) framework to benchmark interpretability methods [22]. Cross-validate findings across multiple preprocessing pipelines and validate against independent neuroscientific literature from genetic, neuroanatomical, and functional studies [22].
Q: Which functional connectivity measure is most sensitive to ASD differences?
A: Multiple measures contribute unique information. Whole-brain intrinsic functional connectivity, particularly interhemispheric and cortico-cortical connections, shows consistent group differences [20]. Additionally, regional metrics like degree centrality and fractional amplitude of low-frequency fluctuations may reveal localized dysfunction [20].
Q: How does pipeline selection specifically impact the direction of findings (e.g., hyper- vs. hypoconnectivity)?
A: Pipeline choices significantly impact connectivity direction findings. One ABIDE analysis found that while both hyper- and hypoconnectivity were present, hypoconnectivity dominated particularly for cortico-cortical and interhemispheric connections [20]. The choice of noise regression strategies, motion correction, and global signal removal can flip the apparent direction of effects.
Experimental Protocols
Protocol 1: Deep Learning Classification with Functional Connectivity
Table 1: Key Parameters for Deep Learning Classification
| Component | Specification | Rationale |
|---|---|---|
| Dataset | ABIDE I (408 ASD, 476 controls after FD filtering) | Large, multi-site sample [22] |
| Preprocessing | Mean FD filtering (>0.2 mm), bandpass filtering (0.01-0.1 Hz) | Reduces motion artifacts, isolates low-frequency fluctuations [22] |
| Model Architecture | Stacked Sparse Autoencoder + Softmax classifier | Captures hierarchical features of functional connectivity [22] |
| Interpretability Method | Integrated Gradients (validated via ROAR) | Provides reliable feature importance attribution [22] |
| Validation | Cross-validation across 3 preprocessing pipelines | Ensures findings not pipeline-specific [22] |
Protocol 2: Surface-Based Morphometry Classification
Table 2: Surface-Based Morphometry Pipeline
| Step | Method | Purpose |
|---|---|---|
| Feature Generation | Multivariate Morphometry Statistics (MMS) | Combines radial distance and tensor-based morphometry [24] |
| Dimension Reduction | Patch-based sparse coding & dictionary learning | Addresses high dimension, small sample size problem [24] |
| Feature Summarization | Max-pooling | Summarizes sparse codes across regions [24] |
| Classification | Ensemble classifiers with adaptive optimizers | Improves generalization performance [24] |
| Validation | Leave-site-out cross-validation | Tests generalizability across scanners [24] |
Protocol 3: Data Harmonization for Multi-Site Studies
Table 3: ComBat Harmonization Protocol
| Stage | Procedure | Outcome |
|---|---|---|
| Data Preparation | Extract connectivity matrices from all sites | Uniform input format |
| Parameter Estimation | Estimate site-specific parameters using empirical Bayes | Quantifies site effects |
| Harmonization | Adjust data using ComBat model | Removes site effects, preserves biological signals |
| Quality Control | Verify removal of site differences using visualization | Ensures successful harmonization |
| Downstream Analysis | Apply machine learning to harmonized data | Improved cross-site classification [21] |
Workflow Visualization
Diagram 1: Explainable AI Pipeline for ASD Classification
Diagram 2: Multi-Site Data Harmonization Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential Tools for ABIDE Data Analysis
| Tool | Function | Application Context |
|---|---|---|
| ComBat Harmonization | Removes site effects while preserving biological signals | Multi-site studies [21] |
| Stacked Sparse Autoencoder | Deep learning for functional connectivity feature extraction | High-accuracy classification [22] |
| Integrated Gradients | Explainable AI method for feature importance | Interpreting model decisions [22] |
| Multivariate Morphometry Statistics | Surface-based shape descriptors | Structural classification [24] |
| Remove And Retrain (ROAR) | Benchmarking framework for interpretability methods | Evaluating feature importance reliability [22] |
| Dual Regression ICA | Data-driven functional network identification | Resting-state network analysis [26] |
| PhiPipe | Multi-modal MRI processing pipeline | Integrated T1, fMRI, and DWI processing [17] |
Troubleshooting Guides
The Neuroimaging Analysis Replication and Prediction Study (NARPS) revealed that when 70 independent teams analyzed the same fMRI dataset, they reported strikingly different conclusions for 5 out of 9 pre-defined hypotheses about brain activity. This variability stemmed from "researcher degrees of freedom"—the many analytical choices researchers make throughout the processing pipeline [27] [28] [29].
Table: Key Factors Contributing to Analytical Variability in NARPS
| Factor | Impact on Results | Example from NARPS |
|---|---|---|
| Spatial Smoothing | Strongest factor affecting outcomes; higher smoothness associated with greater likelihood of significant findings [28] | Smoothness of statistical maps varied widely (FWHM range: 2.50 - 21.28 mm) [28] |
| Software Package | Significant effect on reported results; FSL associated with higher likelihood of significant results vs. SPM [28] | Teams used different software: 23 SPM, 21 FSL, 7 AFNI, 13 Other [28] |
| Multiple Test Correction | Parametric methods led to higher detection rates than nonparametric methods [28] | 48 teams used parametric correction, 14 used nonparametric [28] |
| Model Specification | Critical for accurate interpretation; some teams mis-specified models leading to anticorrelated results [28] | For Hypotheses #1 & #3, 7 teams had results anticorrelated with the main cluster due to model issues [28] |
| Preprocessing Pipeline | No significant effect found from using standardized vs. custom preprocessing [28] | 48% of teams used fMRIprep preprocessed data, others used custom pipelines [28] |
Solution: A Framework for Robust Neuroimaging Analysis
To address the variability uncovered by NARPS, researchers should adopt a multi-framework approach that systematically accounts for analytical flexibility. The goal is not to eliminate all variability, but to understand and manage it to produce more generalizable findings [30].
Table: Solution Framework for Reliable Neuroimaging Analysis
| Strategy | Implementation | Expected Benefit |
|---|---|---|
| Preregistration | Define analysis method before data collection [29] | Reduces "fishing" for significant results; increases methodological rigor |
| Multiverse Analysis | Systematically test multiple plausible analysis pipelines [30] | Maps the space of possible results; identifies robust findings |
| Pipeline Validation | Use reliability (ICC) and predictive validity (age correlation) metrics [17] | Ensures pipelines produce biologically meaningful and consistent results |
| Results Highlighting | Present all results while emphasizing key findings, instead of hiding subthreshold data [31] | Reduces selection bias; provides more complete information for meta-analyses |
| Multi-team Collaboration | Independent analysis by multiple teams with cross-evaluation [29] | Provides built-in replication; identifies methodological inconsistencies |
Experimental Protocols
Original NARPS Experimental Design
The NARPS project collected fMRI data from 108 participants during two versions of the mixed gambles task, which is used to study decision-making under risk [27].
Methodology Details:
- Participants: 108 healthy participants (equal indifference condition: n=54, 30 females, mean age=26.06±3.02 years; equal range condition: n=54, 30 females, mean age=25.04±3.99 years) [27]
- Task Design: Mixed gambles task with 50/50 chance of gaining or losing money [27]
- Imaging Parameters: 4 runs of fMRI, 453 volumes per run, TR=1 second [27]
- Behavioral Measures: Participants responded with "strongly accept," "weakly accept," "weakly reject," or "strongly reject" for each gamble [27]
- Incentive Structure: Real monetary consequences based on randomly selected trial [27]
Systematic Pipeline Evaluation Protocol
Recent advances recommend systematic evaluation of analysis pipelines using multiple criteria beyond simple test-retest reliability [5].
Validation Methodology:
- Reliability Assessment: Calculate Intraclass Correlation (ICC) between repeated scans [17]
- Predictive Validity: Measure correlation between brain features and chronological age [17]
- Multi-criteria Evaluation: Assess sensitivity to individual differences, clinical contrasts, and experimental manipulations [5]
- Portrait Divergence (PDiv): Information-theoretic measure of dissimilarity between network topologies that considers all scales of organization [5]
The Scientist's Toolkit: Research Reagent Solutions
Table: Essential Tools for Reliable Neuroimaging Analysis
| Tool/Category | Function | Application Context |
|---|---|---|
| fMRIPrep | Standardized fMRI data preprocessing | Data preprocessing; used by 48% of NARPS teams [28] |
| PhiPipe | Multi-modal MRI processing pipeline | Generates brain features with assessed reliability and validity [17] |
| FSL, SPM, AFNI | Statistical analysis packages | Main software alternatives with different detection rates [28] |
| Krippendorff's α | Reliability analysis metric | Quantifies robustness of data across pipelines [32] |
| Portrait Divergence | Network topology comparison | Measures dissimilarity between functional connectomes [5] |
| FastSurfer | Deep learning-based segmentation | Automated processing of structural MRI; alternative to FreeSurfer [33] |
| DPARSF/PANDA | Single-modal processing pipelines | Comparison benchmarks for pipeline validation [17] |
Frequently Asked Questions (FAQs)
Q: What was the most surprising finding from the NARPS project?
The most striking finding was that even when teams produced highly correlated statistical maps at intermediate analysis stages, they often reached different final conclusions about hypothesis support. This suggests that thresholding and region-of-interest specification decisions play a crucial role in creating variability [28].
Q: Should we always use standardized preprocessing pipelines like fMRIPrep?
Interestingly, NARPS found no significant effect on outcomes whether teams used standardized preprocessed data (fMRIPrep) versus custom preprocessing pipelines. This suggests that variability arises more from statistical modeling decisions than from preprocessing choices [28].
Q: How can we implement multiverse analysis in our lab without excessive computational cost?
Start by identifying the 3-5 analytical decisions most likely to impact your specific research question. Systematically vary these while holding other factors constant. This targeted approach makes multiverse analysis manageable while still capturing the most important sources of variability [30].
Q: What concrete steps can we take to improve the reliability of our findings?
Based on NARPS and subsequent research: (1) Preregister your analysis plan, (2) Use pipeline validation metrics (reliability and predictive validity), (3) Adopt a "highlighting" approach to results presentation instead of hiding subthreshold findings, and (4) Consider collaborative multi-team analysis for critical findings [31] [29] [30].
Q: Are some brain regions or hypotheses more susceptible to analytical variability?
Yes, NARPS found substantial variation across hypotheses. Only one hypothesis showed high consensus (84.3% significant findings), while three others showed consistent non-significant findings. The remaining five hypotheses showed substantial variability, with 21.4-37.1% of teams reporting significant results [28].
Next-Generation Neuroimaging Pipelines: Deep Learning and Standardization for Scalable Analysis
Troubleshooting Guides
System Requirements and Installation Issues
Q1: What are the minimum system requirements for running DeepPrep, and why is my GPU not being detected?
A: DeepPrep leverages deep learning models for acceleration, making appropriate hardware crucial. The following table summarizes the key requirements:
Table: DeepPrep System Requirements and GPU Troubleshooting
| Component | Minimum Requirement | Recommended Requirement | Troubleshooting Tips |
|---|---|---|---|
| GPU | NVIDIA GPU with Compute Capability ≥ 3.5 | NVIDIA GPU with ≥ 8GB VRAM | Use --device auto to auto-detect or --device 0 to specify the first GPU. For CPU-only mode, use --device cpu. [34] |
| CPU | Multi-core processor | 10+ CPUs | Specify with --cpus 10. [34] |
| Memory | 8 GB RAM | 20 GB RAM | Specify with --memory 20. [34] |
| Software | Docker or Singularity | Latest Docker/Singularity | Ensure --gpus all is passed in Docker or --nv in Singularity. [34] |
| License | - | Valid FreeSurfer license | Pass the license file via -v <fs_license_file>:/fs_license.txt. [34] |
A common issue is incorrect GPU pass-through in containers. For a Docker installation, the correct command must include --gpus all [34]. For Singularity, the --nv flag is required to enable GPU support [34].
Q2: FastSurfer fails during the surface reconstruction phase (recon-surf). What could be the cause?
A: The recon-surf pipeline has specific dependencies on the output of the segmentation step. The issue often lies in the input data or intermediate files.
- Incorrect Input Image Resolution: FastSurfer expects isotropic voxels between 0.7mm and 1.0mm. Verify your input data conforms to this requirement. You can use the
--vox_sizeflag to specify high-resolution behavior. [35] - Failed Volumetric Segmentation: The surface pipeline relies on the high-quality brain segmentation generated by
FastSurferCNN. First, check thesegoutput for obvious errors. Run with--seg_onlyto isolate the segmentation step and visually QC theaparc.DKTatlas+aseg.mgzfile. [35] - Missing FreeSurfer Environment for Downstream Modules: Some downstream analyses, like hippocampal subfield segmentation, require a working installation of FreeSurfer 7.3.2. While FastSurfer creates compatible files, you must source FreeSurfer to run these additional modules. [35]
Runtime Errors and Performance
Q3: The pipeline is running slower than advertised. How can I optimize its performance?
A: Performance depends heavily on your computational resources and data size. The quantitative benchmarks below can help you set realistic expectations.
Table: Performance Benchmarks for DeepPrep and FastSurfer
| Pipeline / Module | Runtime (CPU/GPU) | Speed-up vs. Traditional | Validation Context |
|---|---|---|---|
| DeepPrep (End-to-End) | ~31.6 ± 2.4 min (GPU) | 10.1x faster than fMRIPrep | Processing a single subject from the UK Biobank dataset. [36] |
| DeepPrep (Batch) | ~8.8 min/subject (GPU) | 10.4x more efficient than fMRIPrep | Processing 1,146 subjects per week. [36] |
| FastSurferCNN (Segmentation) | < 1 min (GPU) | Drastic speed-up over FreeSurfer | Whole-brain segmentation into 95 classes. [37] [38] |
| FastSurfer (recon-surf) | ~60 min (CPU) | Significant speed-up over FreeSurfer | Cortical surface reconstruction and thickness analysis. [35] [38] |
| FastCSR (in DeepPrep) | < 5 min | ~47x faster than FreeSurfer | Cortical surface reconstruction from T1-weighted images. [39] |
To optimize performance:
- For DeepPrep: Use the
--cpusand--memoryflags to allocate sufficient resources. For large datasets, leverage its batch-processing capability, which is optimized by the Nextflow workflow manager. [36] [34] - For FastSurfer: Ensure you are using a GPU for the
FastSurferCNNsegmentation step. Therecon-surfpart runs on CPU, and its speed is dependent on single-core performance. [35]
Q4: The pipeline failed when processing a clinical subject with a brain lesion. How can I improve robustness?
A: This is a critical test of pipeline robustness. Deep learning-based pipelines like DeepPrep and FastSurfer have demonstrated superior performance in such scenarios.
- DeepPrep's Robustness: In a test of 53 challenging clinical samples (e.g., with tumors or strokes), DeepPrep achieved a 100% completion rate, with 58.5% being accurately preprocessed. This was significantly higher than fMRIPrep's 69.8% completion and 30.2% accuracy rates. [36] The deep learning modules (FastSurferCNN, FastCSR) are more resilient to anatomical distortions that cause conventional algorithms to fail in skull stripping, surface reconstruction, or registration. [36]
- FastCSR Performance: The FastCSR model, used within DeepPrep, has been successfully applied to reconstruct cortical surfaces for stroke patients with severe cerebral hemorrhage and resulting brain distortion. [39]
- Recommendation: Always perform visual quality checks on the outputs, especially for clinical data. While these pipelines are robust, no automated tool is infallible. [35]
Output and Quality Control
Q5: How can I validate the accuracy of the volumetric segmentations produced by FastSurfer?
A: In the context of reliability assessment, it is essential to verify that the accelerated pipelines do not compromise accuracy. The following experimental protocol can be used for validation.
Validation Protocol: Segmentation Accuracy
- Data Preparation: Utilize a publicly available dataset with manual annotations, such as the Mindboggle-101 dataset [36]. Alternatively, use test-retest data like the OASIS dataset to assess reliability. [38]
- Metric Calculation:
- Dice Similarity Coefficient (DSC): Measures the spatial overlap between the automated segmentation and the manual ground truth. A value of 1 indicates perfect overlap. FastSurferCNN has been shown to outperform other deep learning architectures significantly on this metric. [38]
- Hausdorff Distance: Measures the largest distance between the boundaries of two segmentations, indicating the worst-case error. [38]
- Comparison: Compare the results against traditional pipelines (FreeSurfer) and other deep learning methods. Studies show FastSurfer provides high accuracy that closely mimics FreeSurfer's anatomical segmentation and even outperforms it in some comparisons to manual labels. [37] [38]
Q6: The cortical surface parcellation looks misaligned. Is this a surface reconstruction or registration error?
A: This could be related to either step. The following workflow diagram illustrates the sequence of steps in these pipelines, helping to isolate the problem.
Diagram: Simplified Neuroimaging Pipeline Workflow
- Surface Reconstruction (FastCSR): This step creates the white and pial surface meshes. If the underlying segmentation is incorrect, the surface will be generated in the wrong location. Check the intermediate surfaces for topological correctness. [39]
- Surface Registration (SUGAR): This step maps a standard atlas (e.g., the DKT atlas) from a template sphere to the individual subject's sphere. Misalignment here is a registration error. DeepPrep uses the Spherical Ultrafast Graph Attention Registration (SUGAR) framework for this step, which is a deep-learning-based method designed to be fast and accurate. [36] [40] Ensure that this module completed successfully by checking the pipeline logs.
Frequently Asked Questions (FAQs)
Q: Can these pipelines be used for high-resolution (e.g., 7T) MRI data?
A: Support is evolving. FastSurfer is "transitioning to sub-millimeter resolution support," and its core segmentation module, FastSurferVINN, supports images up to 0.7mm, with experimental support beyond that. [35] DeepPrep lists support for high-resolution 7T images as an "upcoming improvement" on its development roadmap. [40]
Q: What output formats can I expect from DeepPrep?
A: DeepPrep is a BIDS-App and produces standardized outputs. For functional MRI, it can generate outputs in NIFTI format for volumetric data and CIFTI format for surface-based data (using the --bold_cifti flag). It also supports output in standard surface spaces like fsaverage and fsnative. [34]
Q: Are these pipelines suitable for drug development research?
A: Yes, their speed, scalability, and demonstrated sensitivity to group differences make them highly suitable. FastSurfer has been validated to sensitively detect known cortical thickness and subcortical volume differences between dementia and control groups, which is directly relevant to clinical trials in neurodegenerative disease. [38] The ability to rapidly process large cohorts is essential for biomarker discovery and treatment effect monitoring.
The Scientist's Toolkit
This table details the key computational "reagents" and their functions in the DeepPrep and FastSurfer ecosystems.
Table: Key Research Reagent Solutions for Accelerated Neuroimaging
| Tool / Module | Function | Replaces Traditional Step | Key Feature |
|---|---|---|---|
| FastSurferCNN [35] [38] | Whole-brain segmentation into 95 classes. | FreeSurfer's recon-all volumetric stream (hours). |
GPU-based, <1 min runtime. Uses multi-view 2D CNNs with competition. |
| recon-surf [35] [38] | Cortical surface reconstruction, mapping of labels, thickness analysis. | FreeSurfer's recon-all surface stream (hours). |
~1 hour runtime. Uses spectral spherical embedding. |
| FastCSR [36] [39] | Cortical surface reconstruction using implicit level-set representations. | FreeSurfer's surface reconstruction. | <5 min runtime. Robust to image artifacts. |
| SUGAR [36] | Spherical registration of cortical surfaces. | FreeSurfer's spherical registration (e.g., sphere.reg). |
Deep-learning-based graph attention framework. |
| SynthMorph [36] | Volumetric spatial normalization (image registration). | ANTs or FSL registration. | Label-free learning, robust to contrast changes. |
| Nextflow [40] [36] | Workflow manager for scalable, portable, and reproducible data processing. | Manual scripting or linear processing. | Manages complex dependencies and parallelization on HPC/cloud. |
FAQs: Computational Efficiency and Neuroimaging Pipelines
1. What are the most common computational bottlenecks when working with large-scale neuroimaging datasets like the UK Biobank? Common bottlenecks include extensive processing times for pipeline steps, high computational resource demands (memory/CPU), and inefficient scaling with sample size. Benchmarking studies show that different machine learning algorithms have vastly different computational requirements, and some implementations become impracticable at very large sample sizes [41]. Managing these resources efficiently is critical for timely analysis.
2. How does the choice of a neuroimaging data-processing pipeline affect the reliability and efficiency of my results? The choice of pipeline systematically impacts both your results and computational load. Evaluations of fMRI data-processing pipelines reveal "vast and systematic variability" in their outcomes and suitability. An inappropriate pipeline can produce misleading, yet systematically replicable, results. Optimal pipelines, however, consistently minimize spurious test-retest discrepancies while remaining sensitive to biological effects, and do so efficiently across different datasets [5].
3. My processing pipeline is taking too long. What are the first steps I should take to troubleshoot this? Begin by isolating the issue. Identify which specific pipeline step is consuming the most time and resources. Check your computational environment: ensure you are leveraging available high-performance computing or cloud resources like the UK Biobank Research Analysis Platform (UKB-RAP), which provides scalable cloud computing [42]. Furthermore, consult benchmarking resources to see if a more efficient algorithm or model is available for your specific data properties [41].
4. What metrics should I use to evaluate the computational efficiency of a pipeline beyond pure processing time? A comprehensive evaluation should consider several factors: total wall-clock time, CPU hours, memory usage, and how these scale with increasing sample size (e.g., from n=5,000 to n=250,000). It's also crucial to balance efficiency with performance, ensuring that speed gains do not come at the cost of discriminatory power or reliability [41] [5].
5. Are complex models like Deep Learning always better for large-scale datasets like UK Biobank? Not always. Benchmarking on UK Biobank data shows that while complex frameworks can be favored with large numbers of observations and simple predictor matrices, (penalised) COX Proportional Hazards models demonstrate very robust discriminative performance and are a highly effective, scalable platform for risk modeling. The optimal model choice depends on sample size, endpoint frequency, and predictor matrix properties [41].
Troubleshooting Guides
Guide 1: Resolving Extended Processing Times
Problem: Your neuroimaging pipeline is running significantly longer than expected.
Solution: Follow a systematic approach to isolate and address the bottleneck.
- Profile Your Pipeline: Instrument your code to log the time and resource consumption of each major processing step (e.g., T1-weighted segmentation, functional connectivity matrix calculation). This will pinpoint the slowest module.
- Check Resource Allocation: Verify that your job is efficiently using the available CPUs and memory. Under-provisioning can cause queuing and slow performance. On cloud platforms like the UKB-RAP, ensure you have selected an appropriate instance type [42].
- Consult Benchmarks: Refer to existing benchmarking studies. For example, research on the UK Biobank identifies specific scenarios where simpler linear models scale more effectively than complex ones without a significant loss in discriminative performance, offering a potential path to acceleration [41].
- Optimize or Replace the Bottleneck:
- If the bottleneck is a specific atomic software (e.g., a particular segmentation algorithm), investigate if there are faster, validated alternatives.
- Consider if the step can be parallelized across multiple cores or nodes.
- For machine learning models, evaluate if a less computationally intensive model is suitable for your data [41].
Guide 2: Addressing Poor Pipeline Reliability
Problem: Your pipeline yields inconsistent results when run on the same subject at different times (low test-retest reliability).
Solution: A lack of reliability can stem from the pipeline's construction itself.
- Validate Pipeline Components: Systematically evaluate the test-retest reliability of the brain features generated by your pipeline. Use metrics like Intra-class Correlation (ICC) across repeated scans, as demonstrated in pipeline validation studies [17].
- Re-evaluate Pipeline Choices: The specific combination of parcellation, connectivity definition, and global signal regression (GSR) can dramatically impact reliability. Systematic evaluations of fMRI pipelines have identified specific combinations that consistently minimize spurious test-retest discrepancies [5].
- Check for Motion Confounds: Ensure your preprocessing adequately addresses head motion, a major source of spurious variance. The reliability of a pipeline is often judged by its ability to minimize motion confounds [5].
- Adopt a Pre-validated Optimal Pipeline: Instead of building a custom pipeline from scratch, consider adopting a pipeline that has been systematically validated for reliability and predictive validity across multiple datasets [17] [5].
Quantitative Benchmarking Data
Table 1: Benchmarking of Machine Learning Algorithms on UK Biobank-Scale Data
Findings from a comprehensive benchmarking study of risk prediction models, highlighting the trade-off between performance and computational efficiency [41].
| Model / Algorithm Type | Key Performance Findings | Computational & Scaling Characteristics |
|---|---|---|
| (Penalised) COX Proportional Hazards | "Very robust performance" across heterogeneous endpoints and predictor matrices. | Highly effective and scalable; observed as a computationally efficient platform for large-scale modeling. |
| Deep Learning (DL) Models | Can be favored in scenarios with large observations and relatively simple predictor matrices. | "Vastly different" and often impracticable requirements; scaling is highly dependent on implementation. |
| Non-linear Machine Learning Models | Performance is highly dependent on endpoint frequency and predictor matrix properties. | Generally less scalable than linear models; computational requirements can be a limiting factor. |
Table 2: Evaluation Criteria for fMRI Network Construction Pipelines
Summary of the multi-criteria framework used to systematically evaluate 768 fMRI processing pipelines, underscoring that efficiency is not just about speed but also outcome quality [5].
| Criterion | Description | Importance |
|---|---|---|
| Test-Retest Reliability | Minimizes spurious discrepancies in network topology from repeated scans of the same individual. | Fundamental for trusting that results reflect true biology rather than noise. |
| Sensitivity to Individual Differences | Ability to detect meaningful inter-subject variability in brain network organization. | Crucial for studies linking brain function to behavior, traits, or genetics. |
| Sensitivity to Experimental Effects | Ability to detect changes in brain networks due to clinical conditions or interventions (e.g., anesthesia). | Essential for making valid inferences in experimental or clinical studies. |
| Generalizability | Consistent performance across different datasets, scanning parameters, and preprocessing methods. | Ensures that findings and pipelines are robust and not specific to a single dataset. |
Experimental Protocols
Protocol 1: Benchmarking Computational Efficiency of Survival Models
This protocol is derived from the large-scale benchmarking study performed on the UK Biobank [41].
Objective: To compare the discriminative performance and computational requirements of eight distinct survival task implementations on large-scale datasets.
Methodology:
- Data Source: Utilize a large-scale prospective cohort study (e.g., UK Biobank).
- Algorithms: Select a diverse set of machine learning algorithms, ranging from linear models (e.g., penalized COX Proportional Hazards) to deep learning models.
- Experimental Design:
- Scaling Analysis: Systematically vary the sample size (e.g., from n=5,000 to n=250,000 individuals) to assess how processing time and memory usage scale.
- Performance Assessment: Evaluate models based on discrimination metrics (e.g., C-index) across endpoints with different frequencies.
- Resource Tracking: Record wall-clock time, CPU hours, and memory consumption for each model and sample size.
- Analysis: Identify scenarios (defined by sample size, endpoint frequency, and predictor matrix) that favor specific model types. Report on implementations that are impracticable at scale and provide alternative solutions.
Protocol 2: Systematic Evaluation of fMRI Processing Pipelines
This protocol is based on the multi-dataset evaluation of 768 pipelines for functional connectomics [5].
Objective: To identify fMRI data-processing pipelines that yield reliable, biologically relevant brain network topologies while being computationally efficient.
Methodology:
- Pipeline Construction: Systematically combine different options at key analysis steps:
- Global Signal Regression: With vs. without GSR.
- Brain Parcellation: Use different atlases (anatomical, functional, multimodal) with varying numbers of nodes (e.g., 100, 200, 300-400).
- Edge Definition: Pearson correlation vs. mutual information.
- Edge Filtering: Apply different methods (e.g., proportional thresholding, minimum weight, data-driven methods) to produce binary or weighted networks.
- Evaluation Criteria: Assess each pipeline on:
- Reliability: Use Portrait Divergence (PDiv) to quantify test-retest topological dissimilarity within the same individual across short- and long-term intervals.
- Biological Sensitivity: Assess sensitivity to individual differences and experimental effects (e.g., pharmacological intervention).
- Confound Resistance: Evaluate the minimization of motion-related confounds.
- Validation: Require that optimal pipelines satisfy all criteria across multiple independent datasets to ensure generalizability.
Workflow and Pathway Diagrams
DOT Script for Neuroimaging Pipeline Evaluation
DOT Script for Computational Benchmarking Process
The Scientist's Toolkit: Research Reagent Solutions
| Item / Resource | Function / Purpose |
|---|---|
| UK Biobank Research Analysis Platform (UKB-RAP) | A secure, cloud-based platform providing centralized access to UK Biobank data and integrated tools (JupyterLab, RStudio, Apache Spark) for efficient, scalable analysis without local data transfer [42]. |
| PhiPipe | A multi-modal MRI processing pipeline for T1-weighted, resting-state BOLD, and diffusion-weighted data. It generates standard brain features and has published reliability and predictive validity metrics [17]. |
| Linear Survival Models (e.g., COX-PH) | A highly effective and scalable modeling platform for risk prediction on large datasets, often providing robust performance comparable to more complex models [41]. |
| Portrait Divergence (PDiv) | An information-theoretic measure used to quantify the dissimilarity between entire network topologies, crucial for evaluating pipeline test-retest reliability beyond single metrics [5]. |
| High-Performance Computing (HPC) / Cloud Credits | Financial support, such as AWS credits offered via UKB-RAP, to offset the costs of large-scale computational power and storage required for processing massive datasets [42]. |
Troubleshooting Guides
Low Segmentation Accuracy on Clinical MRI Data
Problem: The model trained on public datasets (e.g., ISLES, BraTS) shows poor performance (low Dice score) when applied to hospital data.
Solution: Implement transfer learning and multimodal fusion.
- Root Cause: Scanner variability, different imaging protocols, and population differences between public and private hospital datasets can degrade performance [43].
- Steps for Resolution:
- Utilize Transfer Learning: Initialize your model with weights pre-trained on a larger, diverse neuroimaging dataset before fine-tuning on your target data. For instance, pre-training on the BraTS (brain tumor) dataset has been shown to improve performance on ischemic stroke segmentation tasks [43].
- Adopt a Robust Baseline: Use a framework like nnU-Net, which automatically configures itself based on dataset properties and is known for its robustness in medical image segmentation challenges [43].
- Employ Multimodal Fusion: Leverage multiple MRI sequences. Two effective methods are:
- Joint Training: Train a single model on multiple modalities (e.g., DWI and ADC) simultaneously, then perform inference using the most reliable single modality (e.g., DWI only) [43].
- Channel-wise Training: Concatenate different modalities (e.g., DWI and ADC) as multi-channel inputs to the model [43].
- Ensemble Models: Combine the predictions from different multimodal approaches (e.g., joint training and channel-wise training) to improve generalization and robustness [43].
Handling Small and Imbalanced Neuroimaging Cohorts
Problem: Machine learning models perform poorly or overfit when trained on a small number of subjects, which is common in studies of rare neurological diseases.
Solution: Optimize the ML pipeline and focus on data-centric strategies.
- Root Cause: Limited data fails to capture the full heterogeneity of a disease, making it difficult for models to learn generalizable patterns [44].
- Steps for Resolution:
- Apply Subject-wise Normalization: Normalize features per subject to reduce inter-subject variability, which has been shown to improve classification outcomes in small-cohort studies [44].
- Re-evaluate Pipeline Complexity: Be cautious with aggressive feature selection and dimensionality reduction, as these can provide limited utility or even remove important biomarkers when data is scarce [44].
- Manage Hyperparameter Tuning Expectations: Understand that hyperparameter optimization may yield only marginal gains. Focus effort on other strategies [44].
- Prioritize Data Enrichment: The most effective strategy is often to progressively expand the cohort size, integrate additional imaging modalities, or maximize information extraction from existing datasets [44].
Inadequate Evaluation Beyond Voxel-Wise Metrics
Problem: A model achieves a high Dice score but fails to accurately identify individual lesion burdens, which is critical for assessing disease severity.
Solution: Supplement voxel-wise metrics with lesion-wise evaluation metrics.
- Root Cause: The Dice coefficient measures overall voxel overlap but can be misleading. A model can score highly by correctly segmenting one large lesion while missing several smaller ones [43].
- Steps for Resolution:
- Track Lesion-wise F1 Score: This metric evaluates the accuracy of detecting individual lesion instances, which is more clinically relevant for assessing disease burden [43].
- Monitor Lesion Count Difference: Calculate the absolute difference between the number of true lesions and the number of predicted lesions [43].
- Report Volume Difference: Quantify the difference in the total volume of segmented lesions versus the ground truth [43].
Frequently Asked Questions (FAQs)
Q1: Why is my model's performance excellent on public challenge data but poor on our internal hospital data? A1: This is typically due to the generalization gap. Public datasets are often pre-processed (e.g., skull-stripped, registered to a template) and acquired under specific protocols. Internal clinical data contains more variability. To bridge this gap, use transfer learning from public data, ensure your training incorporates data augmentation, and employ multimodal approaches that enhance robustness [43].
Q2: For ischemic stroke segmentation, which MRI modalities are most crucial? A2: Diffusion-Weighted Imaging (DWI) and the Apparent Diffusion Coefficient (ADC) map are among the most important. DWI is highly sensitive for detecting acute ischemia, while ADC provides quantitative information that can be more robust to observer variability. Using both in a multimodal framework has been shown to significantly improve segmentation performance [43].
Q3: What is a practical baseline model for a new medical image segmentation task? A3: The nnU-Net framework is highly recommended as a robust baseline. It automatically handles key design choices like patch size, data normalization, and augmentation based on your dataset properties, and it has been a top performer in numerous medical segmentation challenges, including ISLES [43].
Q4: How can I improve model performance when I cannot collect more patient data? A4: Focus on pipeline optimization and data enrichment:
- Use transfer learning from a related task (e.g., brain tumor to stroke) [43].
- Integrate all available multimodal data (e.g., T1, T2, FLAIR, DWI) rather than relying on a single modality [44].
- Apply subject-wise feature normalization [44].
- Be strategic with data augmentation to artificially increase dataset size and variability.
Experimental Protocols & Data
Protocol: Multimodal Ensemble for Stroke Segmentation
This protocol is adapted from state-of-the-art methods that ranked highly in the ISLES'22 challenge [43].
Data Preprocessing:
- Use clinical-grade T1-weighted, T2-weighted, FLAIR, DWI, and ADC maps if available.
- For DWI, generate the corresponding ADC map.
- Perform coregistration of all modalities if they are not natively aligned.
- Consider skull-stripping for public data, but note that for clinical application, models should be robust to its absence.
Transfer Learning:
- Obtain a model pre-trained on a large, annotated neuroimaging dataset such as BraTS'21 (for brain tumors).
- This pre-trained model serves as a feature extractor, providing a better initialization than random weights.
Multimodal Model Training:
- Path A (Joint Training): Train a single model (e.g., nnU-Net) on both DWI and ADC modalities. For inference, use only the DWI modality.
- Path B (Channel-wise Training): Train a model using concatenated DWI and ADC images as a two-channel input.
- Use a 5-fold cross-validation strategy on your training data to ensure model stability.
Inference and Ensembling:
- Run inference using both trained models (Path A and Path B) on the test data.
- Combine the segmentation masks from both models via a simple averaging or majority voting scheme to produce the final ensemble prediction.
Quantitative Performance Data
The following table summarizes the performance of a robust ensemble method across multiple datasets, demonstrating its generalizability [43].
Table 1: Segmentation Performance Across Multi-Center Datasets
| Dataset | Description | Sample Size | Dice Coefficient (%) | Lesion-wise F1 Score (%) |
|---|---|---|---|---|
| ISLES'22 | Public challenge dataset (multi-center) | 150 test scans | 78.69 | 82.46 |
| AMC I | External hospital dataset I | Not Specified | 60.35 | 68.30 |
| AMC II | External hospital dataset II | Not Specified | 74.12 | 67.53 |
Note: The AMC I and II datasets represent realistic clinical settings, often without extensive pre-processing like brain extraction, leading to a more challenging environment and lower metrics than the public challenge data.
Table 2: WCAG Color Contrast Ratios for Data Visualization
| Element Type | Minimum Ratio (AA) | Enhanced Ratio (AAA) | Example Use in Diagrams |
|---|---|---|---|
| Standard Body Text | 4.5 : 1 | 7 : 1 | Node text, diagram labels |
| Large Scale Text | 3 : 1 | 4.5 : 1 | Section headers, titles |
| UI Components / Graphics | 3 : 1 | Not Defined | Arrows, diagram symbols |
Signaling Pathways and Workflows
Diagram 1: Neuroimaging Analysis Pipeline
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Components for a Robust Neuroimaging Pipeline
| Item | Function & Rationale |
|---|---|
| nnU-Net Framework | A self-configuring deep learning framework that serves as a powerful and robust baseline for medical image segmentation tasks, automatically adapting to dataset properties [43]. |
| BraTS Pre-trained Weights | Model weights pre-trained on the BraTS dataset (containing T1, T1-CE, T2, and FLAIR modalities) provide an excellent starting point for transfer learning, improving performance on other brain pathology tasks like stroke [43]. |
| DWI & ADC Modalities | Diffusion-Weighted Imaging (DWI) and Apparent Diffusion Coefficient (ADC) are critical multimodal inputs for acute ischemic stroke segmentation, with complementary information that enhances model robustness [43]. |
| Lesion-wise F1 Metric | An evaluation metric that moves beyond voxel-wise Dice to assess the accuracy of detecting individual lesion instances, which is crucial for clinical assessment of disease burden [43]. |
| Subject-wise Normalization | A preprocessing technique that normalizes features on a per-subject basis to reduce inter-subject variability, particularly beneficial in small-cohort studies [44]. |
Core Concepts: BIDS and NiPreps
What are BIDS and NiPreps, and how do they interact to create reproducible neuroimaging workflows?
The Brain Imaging Data Structure (BIDS) is a simple and easy-to-adopt standard for organizing neuroimaging data and metadata in a consistent manner [45]. It establishes formal specifications for file naming, directory structure, and metadata formatting, creating a common language for data organization that eliminates inconsistencies between researchers and labs [45] [19].
NiPreps (NeuroImaging PREProcessing toolS) are a collection of robust, automated preprocessing pipelines that consume BIDS-formatted data and produce "analysis-grade" derivatives [46]. These pipelines are designed to be robust across diverse datasets, easy to use with minimal manual input, and transparent in their operations through comprehensive visual reporting—principles collectively known as the "glass box" philosophy [47] [46].
The interaction between these frameworks creates a seamless pathway for reproducible analysis: BIDS standardizes the input data, while NiPreps perform standardized preprocessing operations on that data, with both using the BIDS-Derivatives extension to standardize output data organization [19]. This end-to-end standardization significantly reduces analytical variability, a major factor undermining reliability in neuroimaging research [19] [46].
Diagram: The Standardized Neuroimaging Workflow Ecosystem
Why is standardization critical for reliability assessment in neuroimaging pipelines?
Standardization addresses the critical problem of methodological variability in neuroimaging research. The Neuroimaging Analysis Replication and Prediction Study (NARPS) demonstrated this issue starkly when 70 independent teams analyzing the same fMRI dataset produced widely varying conclusions, primarily due to differences in their analytical workflows [19] [46]. This variability stems from several factors:
- Implementation differences: The same algorithmic step may yield different results across software packages [46]
- Parameter selection: Researchers make different choices in processing parameters and workflow design [19]
- Reporting deficiencies: Incomplete method descriptions prevent exact replication [19]
BIDS and NiPreps counter these problems by providing a standardized framework for both data organization and preprocessing implementation. This standardization enables true reliability assessment by ensuring that observed variability in results stems from biological or technical factors rather than from inconsistencies in data management or processing methods [19].
Troubleshooting Guides & FAQs
BIDS Compliance Issues
Q: How can I quickly identify and fix BIDS validation errors in my dataset?
Problem: Your dataset fails BIDS validation, preventing its use with BIDS Apps like NiPreps.
Diagnosis and Solution:
Table: Common BIDS Validation Errors and Solutions
| Error Type | Root Cause | Solution Steps | Prevention Tips |
|---|---|---|---|
| File naming violations | Incorrect entity labels or ordering | 1. Run BIDS validator locally or via web interface2. Review error report for specific naming issues3. Use BIDS-compliant naming convention: sub-<label>_ses-<label>_task-<label>_acq-<label>_ce-<label>_rec-<label>_run-<index>_<contrast_label> [45] |
Consult BIDS specification early in experimental design |
| Missing mandatory metadata | Required JSON sidecar files incomplete or missing | 1. Identify missing metadata fields from validator output2. Create appropriate JSON files with required fields3. For MRI: Ensure TaskName, RepetitionTime, EchoTime are specified [45] |
Use BIDS starter kits when setting up new studies |
| File format incompatibility | Non-standard file formats or extensions | 1. Convert proprietary formats to NIfTI for imaging data2. Use TSV for tabular data (not CSV)3. Include .json sidecar files for metadata [45] |
Implement data conversion in acquisition phase |
Verification: After corrections, revalidate your dataset using the official BIDS validator (available online or as a command-line tool) until no errors are reported [45].
Q: My specialized modality isn't fully supported in BIDS. How should I proceed?
Problem: You're working with a neuroimaging modality or experimental design that isn't completely covered by the core BIDS specification.
Solution Approach:
- Check extension proposals: BIDS is a community-driven standard with multiple modality extensions (MEG, EEG, iEEG, PET, microscopy, etc.) that may cover your needs [45]
- Use closest existing convention: Adapt the most similar supported modality while maintaining consistency with BIDS principles
- Document thoroughly: Clearly describe your adaptations in a README file and dataset_description.json
- Community engagement: Contribute to BIDS extension proposals to formalize support for your modality [45]
NiPreps Implementation Issues
Q: How do I resolve common fMRIPrep/sMRIPrep preprocessing failures?
Problem: NiPreps pipelines fail during execution with error messages related to specific processing steps.
Diagnosis and Solution:
Table: Frequent NiPreps Processing Failures and Resolution Strategies
| Failure Scenario | Error Indicators | Debugging Steps | Advanced Solutions |
|---|---|---|---|
| Insufficient fieldmap metadata | "No B0 field information available" or missing distortion correction | 1. Verify IntendedFor tags in fieldmap JSON files2. Check for TotalReadoutTime or EchoTime differences in phase encoding directions3. Confirm fieldmap data structure matches BIDS specification [48] |
Implement SDCFlows directly for complex fieldmap scenarios [48] |
| Motion correction failures | Excessive motion warnings, pipeline termination | 1. Check input data quality with MRIQC2. Review visual reports for evident artifacts3. Consider acquiring additional motion correction scans if available | For extreme motion, use --dummy-scans option or increase --fd-spike-threshold |
| Normalization/registration issues | Poor alignment to template space in visual reports | 1. Verify template availability in TemplateFlow2. Check if subject anatomy is substantially different from template3. Review segmentation accuracy in reports | Use --skull-strip-t1w force or --skull-strip-fixed-seed for problematic extractions |
| Memory or computational resource exhaustion | Pipeline crashes with memory errors | 1. Allocate sufficient resources (typically 8-16GB RAM per subject)2. Use --mem_mb and --nprocs to limit resource usage3. Enable --notrack to reduce memory overhead |
Process subjects individually or in smaller batches |
Proactive Strategy: Always examine the visual reports generated by NiPreps for each subject, as they provide comprehensive insights into processing quality and potential failure points [47] [46].
Q: What strategies ensure successful NiPreps implementation for large-scale datasets?
Problem: Processing hundreds or thousands of subjects presents computational, organizational, and reproducibility challenges.
Solution Framework:
- Containerized execution: Use Docker or Singularity containers for consistent software environments across computing platforms [46]
- Scalable workflow management: Employ tools like BABS (BIDS App Bootstrap) for reproducible processing at scale, which leverages DataLad for version control and audit trails [49]
- Parallel processing: Distribute subjects across high-performance computing resources using Sun Grid Engine (SGE) or Slurm workload managers [49]
- Quality assessment automation: Implement automated quality control pipelines using MRIQC to identify problematic datasets before intensive processing [46]
Integration and Advanced Application Issues
Q: How can I extend NiPreps for novel analyses or specialized populations?
Problem: Standard NiPreps configurations don't support your specialized research needs, such as rodent data, infant populations, or novel modalities.
Solution Pathways:
Table: NiPreps Extension Frameworks for Specialized Applications
| Application Scenario | Current Solutions | Implementation Approach | Development Status |
|---|---|---|---|
| Rodent neuroimaging | NiRodents framework | 1. Use fMRIPrep-rodents specialization2. Adapt template spaces to appropriate rodent templates3. Modify processing parameters for rodent neuroanatomy [50] | Active development, community testing [50] |
| Infant/pediatric processing | Nibabies pipeline | 1. Leverage age-specific templates2. Account for rapid developmental changes in tissue properties3. Adjust registration and normalization approaches [50] | Production-ready for various age ranges |
| PET imaging preprocessing | PETPrep application | 1. Utilize for motion correction, segmentation, registration2. Perform partial volume correction3. Extract time activity curves for pharmacokinetic modeling [51] | Stable release, active maintenance [51] |
| Multi-echo fMRI denoising | fMRIPost-tedana integration | 1. Run fMRIPrep with --me-output-echos flag2. Apply tedana to denoise multi-echo data3. Generate combined BOLD timeseries with noise components removed [50] |
Under active development [50] |
Development Philosophy: The NiPreps ecosystem is designed for extensibility, with modular architecture based on NiWorkflows that enables community-driven development of specialized preprocessing approaches [50] [46].
Implementation Protocols
Standard Operating Procedure: Implementing a Reliable BIDS-NiPreps Pipeline
Protocol Objective: Establish a standardized workflow from raw data to analysis-ready derivatives using BIDS and NiPreps.
Materials and Software Requirements:
Table: Essential Research Reagents and Computational Tools
| Component | Specific Tools/Formats | Function/Purpose | Availability |
|---|---|---|---|
| Data organization standard | BIDS specification | Consistent structure, naming, and metadata formatting | bids.neuroimaging.io |
| Core preprocessing pipelines | fMRIPrep, sMRIPrep, QSIPrep, PETPrep | Robust, standardized preprocessing for various modalities | nipreps.org |
| Quality assessment tools | MRIQC, PETQC (in development) | Automated extraction of image quality metrics | nipreps.org |
| Containerization platforms | Docker, Singularity, Podman | Reproducible software environments | Container repositories |
| Data management systems | DataLad, BABS | Version control and audit trails for large datasets | GitHub repositories |
| Template spaces | TemplateFlow | Standardized reference templates for spatial normalization | templateflow.org |
Step-by-Step Procedure:
BIDS Conversion Phase (Duration: 1-3 days for typical study)
- Organize raw DICOM data into structured directories
- Convert to NIfTI format using tools like dcm2niix
- Create BIDS-compliant file names and directory structure
- Generate mandatory dataset description files (
dataset_description.json,participants.tsv) - Add modality-specific metadata in JSON sidecar files
- Validate using BIDS validator (command line or web interface)
Quality Screening Phase (Duration: 2-4 hours for typical dataset)
- Run MRIQC on BIDS dataset to identify acquisition issues
- Review group quality metrics for outliers
- Examine individual image quality for obvious artifacts
- Document any dataset limitations for downstream interpretation
NiPreps Execution Phase (Duration: 4-8 hours per subject, depending on data complexity)
- Select appropriate NiPreps pipeline for modality (fMRIPrep, sMRIPrep, etc.)
- Configure computational resources based on dataset size
- Execute using containerized implementation
- Monitor processing logs for warnings or errors
- Generate comprehensive visual reports for each subject
Output Verification Phase (Duration: 30-60 minutes per subject)
- Review visual reports for registration accuracy, artifact correction
- Verify output structure compliance with BIDS-Derivatives
- Check processing metadata for complete method documentation
- Confirm derivative files are suitable for planned downstream analyses
Data Preservation Phase (Duration: Variable)
- Archive both input BIDS data and output derivatives
- Preserve container specifications for computational reproducibility
- Document any custom configurations or parameters used
- Prepare data for sharing via repositories like OpenNeuro [45]
Diagram: End-to-End Standardized Processing Workflow
Troubleshooting Notes:
- For BIDS conversion challenges, consult the BIDS starter kit for examples and templates [45]
- If NiPreps fail due to memory issues, reduce parallel processing with
--nprocsflag - When working with non-human data, utilize species-appropriate NiPreps variants [50]
- For unconventional study designs, consider contributing to the open-source NiPreps ecosystem to extend functionality [46]
The Scientist's Toolkit
Table: Critical Tools and Resources for Reproducible Pipeline Implementation
| Resource Category | Specific Tools/Resources | Key Functionality | Application Context |
|---|---|---|---|
| Data Standards | BIDS Specification, BIDS-Derivatives | Data organization, metadata specification, output standardization | All neuroimaging modalities, mandatory for NiPreps compatibility [45] |
| Core Pipelines | fMRIPrep, sMRIPrep, QSIPrep, PETPrep | Minimal preprocessing, distortion correction, spatial normalization | fMRI, structural MRI, diffusion MRI, PET data respectively [51] [47] [46] |
| Quality Assessment | MRIQC, PETQC (development) | Image quality metrics, automated outlier detection | Data screening, processing quality evaluation [50] [46] |
| Containerization | Docker, Singularity | Reproducible software environments, dependency management | Cross-platform deployment, computational reproducibility [49] [46] |
| Workflow Management | BABS (BIDS App Bootstrap), NiWorkflows | Large-scale processing, audit trails, workflow architecture | High-performance computing,大规模studies [49] |
| Community Support | NeuroStars Forum, GitHub Issues | Troubleshooting, method discussions, bug reporting | Problem resolution, knowledge exchange [47] |
Validation and Verification Framework
Protocol for Pipeline Reliability Assessment:
Cross-validation implementation:
- Process subsets of data with different computational resources
- Compare outputs across processing environments
- Verify checksum consistency for critical derivative files
Methodological consistency monitoring:
- Document all software versions and container images
- Preserve exact command-line invocations
- Maintain comprehensive processing logs
Output quality benchmarking:
- Establish quality metric thresholds based on population norms
- Implement automated flagging of suboptimal processing
- Maintain visual inspection protocols for critical processing steps
This structured approach to implementing standardized workflows using BIDS and NiPreps ensures that neuroimaging pipeline reliability assessment research builds upon a foundation of methodological consistency, computational reproducibility, and transparent reporting—essential elements for advancing robust and replicable brain science.
Troubleshooting Common Portability Issues
| Problem Area | Common Symptoms | Likely Cause | Solution |
|---|---|---|---|
| Software Dependencies | Inconsistent results across systems; "library not found" errors; workflow fails on one cluster but works on another. | Differing versions of underlying system libraries (e.g., MPI, BLAS) or the neuroimaging software itself between computing environments [52]. | Use containerized software (e.g., Neurocontainers, Docker) to package the application and all its dependencies into a single, portable unit [52] [53]. |
| Environment Variables & Paths | Workflow cannot locate data or configuration files; "file not found" errors when moving between HPC and a local machine. | Hard-coded file paths or environment variables that are specific to one computing environment [53]. | Use relative paths within a defined project structure. Leverage workflow managers or container environments that can dynamically set or map paths. |
| MPI & Multi-Node Communication | Jobs hanging during multi-node execution; performance degradation on a new cluster. | Incompatibility between the version of MPI used in the container and the version on the host system's high-speed network fabric (e.g., InfiniBand) [53]. | Use HPC-specific containers that are built to be compatible with the host's MPI library, often through the use of bind mounts or specialized flags [53]. |
| Data Access & Permissions | Inability to read/write data from within a container; permission denied errors. | User permissions or file system structures (e.g., Lustre) not being correctly mapped into the containerized environment [53]. | Ensure data directories are properly mounted into the container. On HPC systems, verify that the container runtime is configured to work with parallel file systems. |
Frequently Asked Questions (FAQs)
Q1: What is the core difference between a portable workflow and a standard one? A standard workflow often relies on software installed directly on a specific operating system, making it vulnerable to "dependency hell" where conflicting or missing libraries break the process. A portable workflow uses containerization (e.g., Docker, Singularity) to encapsulate the entire analysis environment—the tool, its dependencies, and even the OS layer. This creates a self-contained unit that can run consistently on any system with a container runtime, from a laptop to a high-performance computer (HPC) cluster [52] [53].
Q2: Our team uses both personal workstations and an HPC cluster. How can containerization help? Containerization is ideal for this hybrid scenario. You can develop and prototype your neuroimaging pipeline (e.g., using FSL, FreeSurfer, fMRIPrep) in a container on your local machine. That exact same container can then be submitted as a job to your HPC cluster, ensuring that the results are consistent and reproducible across both environments. This eliminates the "it worked on my machine" problem [52] [54].
Q3: We want to ensure our published neuroimaging results are reproducible. What is the best practice? The highest standard of reproducibility is achieved by using versioned containers. Platforms like Neurodesk provide a comprehensive suite of neuroimaging software containers where each tool and its specific version are frozen with all dependencies [52]. By documenting the exact container version used in your research, other scientists can re-execute your analysis years later and obtain the same results, independent of their local software installations [55].
Q4: What are the main challenges in using containers on HPC systems, and how are they solved? The primary challenge is integrating containers with specialized HPC hardware, particularly for multi-node, parallel workloads that use MPI. Traditional web application containers are not built for this. Solutions involve HPC-specific containers that are designed to be compatible with the host's networking stack and schedulers (like Slurm), allowing for seamless scaling without sacrificing performance [53].
Experimental Evidence: Quantifying Portability Benefits
The following table summarizes a key experiment that demonstrates how containerization prevents environmental variability from affecting neuroimaging results.
| Experimental Component | Methodology Description |
|---|---|
| Objective | To evaluate whether Neurodesk, a containerized platform, could eliminate result variability across different computing environments [52]. |
| Protocol | Researchers ran four identical MRI analysis pipelines on two separate computers. For each computer, the pipelines were executed twice: once using software installed locally on the system, and once using the containerized software provided by Neurodesk [52]. |
| Key Comparison | The outputs from the two different computers were compared for both the locally installed and the containerized runs. |
| Results (Local Install) | The study found "meaningful differences in image intensity and subcortical tissue classification between the two computers for pipelines run on locally installed software" [52]. |
| Results (Containerized) | For the pipelines run using Neurodesk containers, no meaningful differences were observed between the results generated on the two different computers [52]. |
| Conclusion | Containerization allows researchers to adhere to the highest reproducibility standards by eliminating a significant source of technical variability introduced by the computing environment [52]. |
The Scientist's Toolkit: Essential Research Reagents & Materials
| Item Name | Function in the Experiment |
|---|---|
| Software Containers (e.g., Docker, Singularity/Apptainer) | The fundamental tool for portability. They encapsulate a complete runtime environment: the application, all its dependencies, libraries, and configuration files [52] [53]. |
| Workflow Manager (e.g., Nextflow, Snakemake) | Orchestrates the execution of multiple, sequential processing steps (often each in their own container). Handles task scheduling, dependency resolution, and failure recovery, making complex pipelines portable and scalable [55]. |
| HPC Job Scheduler (e.g., Slurm, PBS Pro) | Manages computational resources on a cluster. A portable workflow is submitted to this system, which allocates CPU, GPU, and memory, and then executes the job, often by launching a container [53]. |
| Message Passing Interface (MPI) Library | Enables parallel computing by allowing multiple processes (potentially running on different nodes of a cluster) to communicate with each other. Essential for scaling demanding computations [53]. |
| Data Versioning Tool (e.g., DataLad) | Manages and tracks versions of often large neuroimaging datasets. Ensures that the correct version of input data is used in an analysis, contributing to overall reproducibility and portability [54]. |
Workflow Architecture for a Portable Neuroimaging Analysis
The following diagram illustrates the logical structure and component relationships of a portable neuroimaging analysis system.
Experimental Protocol for Assessing Pipeline Reliability
This diagram outlines a methodology for testing the reliability of a neuroimaging pipeline across different computing environments.
Optimizing Pipeline Performance: Strategies for Robustness and Individualized Analysis
Frequently Asked Questions
What is the primary difference between manual and automated outlier detection?
Manual outlier detection relies on researcher expertise to visually identify anomalies in data, while automated methods use algorithms and statistical models to flag data points that deviate from expected patterns. Manual review offers high contextual understanding but is time-consuming and subjective. Automated processes provide consistency and speed, scaling well with large datasets, but may lack nuanced judgment and require careful parameter tuning to avoid missing complex outliers or flagging valid data.
When should I prioritize manual review over automated methods?
Prioritize manual review in the early stages of a new research protocol, when the nature of outliers is not yet well-defined, or when dealing with very small, high-value datasets. Manual checks are also crucial for validating and refining the rules of a new automated pipeline. Once a consistent pattern of outliers is understood, these rules can often be codified into an automated script.
How can I handle poor-quality data that is not a clear outlier?
Data of marginal quality should be handled through pruning choices within your analysis pipeline. The approach (e.g., excluding channels with low signal-to-noise ratio, using correlation-based methods to reject noisy trials, or applying robust statistical models) must be consistently documented. Research shows that how different teams handle this poor-quality data is a major source of variability in final results [56].
My automated detector is flagging too many valid data points. How can I improve it?
This is typically a problem of specificity. You can improve your detector by: reviewing a subset of flagged data to understand false positive patterns, adjusting your detection thresholds (e.g., Z-score or deviation thresholds), using a different statistical model better suited to your data's distribution, or incorporating multivariate analysis that considers the relationship between multiple parameters instead of examining each one in isolation.
Why do different research teams analyzing the same dataset find different outliers?
Substantial variability in outlier detection results from analytical choices across different pipelines [56]. Key sources of this variability include the specific preprocessing steps applied, the statistical models and threshold values chosen for detection, and how the hemodynamic response is modeled in neuroimaging data. This highlights the critical need for transparent reporting of all methodological choices in your QC procedures.
Comparison of Outlier Detection Methods
| Feature | Manual Detection | Automated Detection |
|---|---|---|
| Basis of Detection | Researcher expertise and visual inspection [56] | Algorithmic rules and statistical models |
| Throughput/Scalability | Low; time-consuming for large datasets | High; efficient for large, multimodal data [44] |
| Objectivity & Consistency | Low; susceptible to subjective judgment and expectation bias [56] | High; provides consistent, reproducible results |
| Contextual Understanding | High; can incorporate complex, non-quantifiable factors | Low; limited to predefined parameters and models |
| Optimal Use Case | Small cohorts, novel paradigms, validating automated pipelines [44] | Large-scale studies, established protocols, routine QC |
Experimental Protocols for Key Methodologies
Protocol 1: Community-wide Analysis of Pipeline Variability (FRESH Initiative)
The FRESH initiative provides a framework for assessing how analytical choices impact outlier detection and results [56].
- Dataset Distribution: Provide multiple independent research teams with the same raw neuroimaging dataset (e.g., fNIRS or MRI data).
- Hypothesis Testing: Teams are given a set of pre-defined hypotheses to test but receive no instructions on the analysis pipeline.
- Independent Analysis: Each team processes the data, performs quality control (including their chosen method of outlier detection and handling), and analyzes it using their own preferred pipeline.
- Result Aggregation: Teams submit their statistical outcomes and a detailed description of their analysis pipeline.
- Variability Analysis: Synthesize results to quantify agreement between teams and identify which specific stages of the pipeline (e.g., data pruning, HRF modeling, statistical inference) are the primary sources of variability.
Protocol 2: Machine Learning Pipeline Evaluation for Small Cohorts
This protocol is designed for systematic evaluation of ML pipelines under data-constrained conditions, common in rare disease studies [44].
- Cohret Description: Acquire multimodal MRI data from a limited cohort (e.g., 16 patients, 14 healthy controls) [44].
- Data Pre-processing: Apply necessary pre-processing steps (e.g., denoising, motion correction, skull-stripping) to generate parametric maps.
- Pipeline Configuration: Systematically evaluate the impact of various pipeline components, including:
- Feature scaling and normalization methods.
- Feature selection and dimensionality reduction techniques.
- Hyperparameter optimization strategies.
- Performance Assessment: Evaluate the classification performance of different pipeline configurations to determine which components most significantly impact outcomes with limited data.
Workflow Diagrams
Pipeline Variability Analysis
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function |
|---|---|
| 7T MRI Scanner | High-field magnetic resonance imaging system for acquiring high-resolution structural and functional data [44]. |
| Multimodal MRI Protocols | A set of imaging sequences (e.g., MP2RAGE for T1-weighting, DTI for diffusion) to generate complementary parametric maps from a single scanning session [44]. |
| fNIRS Hardware | Functional near-infrared spectroscopy system for measuring brain activity via hemodynamic responses, useful in naturalistic settings [56]. |
| Automated Processing Scripts | Custom or off-the-shelf scripts (e.g., in Python or R) for applying consistent preprocessing, feature extraction, and initial automated outlier detection. |
| Statistical Analysis Software | Tools (e.g., SPM, FSL, custom ML libraries) for performing group and individual-level statistical inference and hypothesis testing [44] [56]. |
| Data Pruning Tools | Software utilities or scripts to handle poor-quality data, such as excluding low-signal channels or motion-corrupted timepoints [56]. |
Troubleshooting Guides
FAQ: Why does my automated segmentation still require manual editing, and how can I identify errors?
Answer: Automated segmentation tools like FreeSurfer, while powerful, can produce errors even in structurally normal brains due to factors like image quality, anatomical variation, and the presence of pathology. These errors are often categorized as unconnected (affecting a single Region of Interest) or connected (affecting multiple ROIs), and can be further classified by size (minor, intermediate, major) and directionality (overestimation or underestimation) [10].
Identification Methodology: EAGLE-I (ENIGMA's Advanced Guide for Parcellation Error Identification) provides a systematic protocol for visual quality control [10]:
- Error Typing: Classify errors as affecting single or multiple ROIs.
- Size Assessment: Estimate the percentage of the region affected.
- Directionality: Determine if the error is an overestimation or underestimation of the neuroanatomical boundaries.
- Use a standardized error tracker spreadsheet to record findings consistently.
Quantitative Data on Segmentation Error Impact:
- Clinical Populations: In patients with conditions like moderate-to-severe Traumatic Brain Injury (ms-TBI), pathology can exacerbate typical parcellation errors, directly impacting downstream analyses [10].
- Generalizability: Deep learning models like FastSurferCNN have demonstrated high segmentation accuracy on several unseen datasets, showing good generalizability and increased test-retest reliability compared to some conventional methods [33].
FAQ: What are the common cortical surface reconstruction failures and their solutions?
Answer: Surface reconstruction errors occur when the generated white or pial surfaces do not accurately follow the actual gray matter/white matter boundaries. Common failures include pial surface misplacement and topological defects [16].
Troubleshooting Protocol:
- Initial Check: Always manually inspect the output of your reconstruction, even if the process finishes without reported errors [16].
- Key Questions: Ask yourself:
- Do the surfaces follow the gray matter/white matter borders?
- Does the subcortical segmentation follow intensity boundaries?
- If the answer to either is 'no', manual editing is required [16].
- Primary Fixes: The main methods for correcting these errors are erasing voxels, filling voxels, cloning voxels (copying from one volume to another), and adding "control points" [16].
Next-Generation Solutions:
- FastCSR: A deep learning-based pipeline that learns an implicit "level set representation" of the cortical surface. It is capable of reconstructing cortical surfaces within 5 minutes with comparable quality to traditional methods, offering a significant speedup and demonstrating robustness in brains with lesions or distortions [57].
- DeepPrep: An integrated pipeline that uses FastCSR for surface reconstruction. It has shown a 100% pipeline completion ratio on challenging clinical samples that traditional pipelines failed to process within 48 hours [58].
FAQ: How can I efficiently and reliably perform quality control on brain registration?
Answer: Registration aligns individual brain images to a standard space and is prone to failure. A standardized QC protocol is crucial for reliable results [59].
Standardized QC Protocol for Brain Registration [59]:
- Rating System: Use a three-level rating: OK, Maybe, Fail.
- Procedure: The protocol is designed to require minimal training and no expert knowledge of neuroanatomy.
- Reliability: Achieves moderate to good agreement between expert raters (kappa: 0.4 to 0.68). The highest agreement is for identifying "Fail" images.
- Crowdsourcing: The protocol is validated for use with non-expert raters via crowdsourcing platforms. Aggregating ratings from a panel of non-experts (minimum 15) can yield high consensus with expert panels.
Protocol for Functional MRI Registration QC [60]:
- Tool: Utilizes
pyfMRIqcto generate visual reports of data quality. - Classification: Data is classified as "include," "uncertain," or "exclude."
- Reliability: Shows moderate to substantial agreement for "include" and "exclude" decisions, but lower agreement for "uncertain" cases. Recommendations include clear qualitative and quantitative criteria to reduce rater disagreement.
Experimental Protocols & Methodologies
Protocol: Visual Quality Control of Anatomical Parcellation using EAGLE-I
Purpose: To systematically identify, classify, and record parcellation errors in individual brain regions [10].
Materials:
- Parcellation images (e.g., from FreeSurfer or FastSurfer using the Desikan-Killiany atlas).
- EAGLE-I error tracker spreadsheet.
Procedure:
- Load the parcellation image and the original T1-weighted image in a viewer capable of overlaying them.
- Inspect each brain region in turn.
- For each Region of Interest (ROI): a. Determine if an error is present. b. If an error exists, classify it: * Type: Unconnected (affects one ROI) or Connected (affects multiple ROIs). * Size: Minor, Intermediate, or Major (based on estimated percentage of the ROI affected). * Direction: Overestimation or Underestimation of the true anatomical boundary.
- Record the classification for each ROI in the EAGLE-I error tracker using predefined codes.
- The error tracker will automatically calculate an overall image quality rating (e.g., Pass, Minor Error, Major Error, Fail, Discuss) based on the accumulated region-level errors.
Protocol: Evaluating Pipeline Reliability and Validity
Purpose: To assess the test-retest reliability and predictive validity of a neuroimaging pipeline's output features, which is critical for informing experimental design and analysis [17].
Materials:
- A dataset with repeated scans from the same participants (for reliability).
- A dataset with participants across an adult lifespan (for validity, using age as a proxy).
Procedure:
- Test-Retest Reliability: a. Process all repeated scans through the pipeline. b. For each brain feature of interest (e.g., cortical thickness, regional volume), calculate the Intra-class Correlation Coefficient (ICC) across the repeated scans. c. ICC values indicate the consistency of the feature measurement: higher values indicate better reliability.
- Predictive Validity: a. Process the lifespan dataset through the pipeline. b. For each brain feature, compute its correlation with chronological age. c. A strong, reproducible correlation with age demonstrates the feature's validity for detecting biological changes.
Data Presentation
Table: Comparison of Neuroimaging Pipelines and Their Performance
| Pipeline Name | Primary Function | Key Features / Technology | Processing Time (Per Subject) | Key Performance Metrics |
|---|---|---|---|---|
| FreeSurfer [16] | Anatomical segmentation & surface reconstruction | Conventional computer vision algorithms | Several hours | Prone to segmentation and surface errors requiring manual inspection; benchmark for accuracy. |
| FastSurfer [33] | Anatomical segmentation & surface replication | Deep Learning (Competitive Dense Blocks) | Volumetric: <1 min; Full thickness: ~1 hr | High segmentation accuracy, increased test-retest reliability, sensitive to group differences. |
| FastCSR [57] | Cortical Surface Reconstruction | Deep Learning (3D U-Net, Level Set Representation) | < 5 minutes | 47x faster than FreeSurfer; good generalizability; robust to lesions. |
| DeepPrep [58] | Multi-modal Preprocessing (Structural & Functional) | Deep Learning modules + Nextflow workflow manager | ~31.6 min (with GPU) | 10x faster than fMRIPrep; 100% completion on difficult clinical cases; highly scalable. |
| PhiPipe [17] | Multi-modal MRI Processing | Relies on FreeSurfer, AFNI, FSL; outputs atlas-based features | N/S | Evaluated via ICC (reliability) and age correlation (validity); results consistent or better than other pipelines. |
Table: Quality Control Protocols and Their Reported Reliability
| QC Protocol | Modality | Rating Scale | Inter-Rater Agreement (Primary Metric) | Key Application Context |
|---|---|---|---|---|
| Standardized Registration QC [59] | Structural (T1) | OK, Maybe, Fail | Kappa = 0.54 (average experts); 0.76 (expert vs. crowd panel) | Brain registration for fMRI studies; minimal neuroanatomy knowledge required. |
| EAGLE-I [10] | Structural (Parcellation) | Error size: Minor, Intermediate, Major; Final image rating: Pass, Minor Error, etc. | Aims to reduce variability via standardized criteria and tracking. | Detailed region-level error identification for cortical parcellations, especially in clinical populations (e.g., TBI). |
| pyfMRIqc Protocol [60] | Functional (fMRI) | Include, Uncertain, Exclude | Moderate to substantial for Include/Exclude; low for Uncertain. | Quality assessment of raw and minimally pre-processed task-based and resting-state fMRI data. |
Workflow and Relationship Diagrams
Neuroimaging Pipeline Failure Points and Solutions
Diagram: Neuroimaging Failure and Solution Workflow
The Scientist's Toolkit: Research Reagents & Solutions
Table: Essential Tools for Neuroimaging Pipeline QC and Improvement
| Tool / Resource | Function | Brief Description / Utility |
|---|---|---|
| Freeview (FreeSurfer) [16] | Visualization & Manual Editing | Primary tool for visually inspecting and manually correcting segmentation and surface errors (e.g., editing brainmask.mgz, wm.mgz). |
| EAGLE-I Error Tracker [10] | Standardized Error Logging | A customized spreadsheet with standardized coding for recording parcellation errors, enabling automatic calculation of final image quality ratings. |
| pyfMRIqc [60] | fMRI Quality Assessment | Generates user-friendly visual reports and metrics for assessing the quality of raw and pre-processed fMRI data, aiding include/exclude decisions. |
| FastCSR [57] [58] | Accelerated Surface Reconstruction | A deep learning model for rapid, topology-preserving cortical surface reconstruction, robust to image quality issues and brain distortions. |
| DeepPrep [58] | Integrated Preprocessing | A comprehensive, scalable pipeline integrating multiple deep learning modules (e.g., FastCSR, SUGAR) for efficient structural and functional MRI processing. |
| ICC (Intra-class Correlation) [17] | Reliability Metric | A critical statistical measure for quantifying the test-retest reliability of continuous brain features (e.g., cortical thickness, volume) generated by a pipeline. |
Troubleshooting Guide: Common Pipeline Optimization Issues
FAQ: My pipeline works well on one dataset but fails on another. Why?
This is a classic sign of cohort-specific effects, a major challenge in neuroimaging. The optimal preprocessing pipeline can vary significantly based on the characteristics of your study population.
- Root Cause: Different cohorts exhibit varying levels of noise confounds. For example, older adults consistently show significantly higher head motion than younger adults during scanning [61] [62]. Age-related changes in neurovascular coupling and physiological noise (like cardiac pulsation) also alter the underlying noise structure that preprocessing aims to correct [62].
- Diagnosis Steps:
- Quantify potential confounds like motion (Mean Framewise Displacement) for each subject group and compare their distributions.
- Check for systematic differences in data quality metrics (e.g., Signal-to-Noise Ratio, contrast-to-noise ratio) between your datasets.
- Solution: Implement an adaptive optimization framework instead of using a single fixed pipeline. Use cross-validation frameworks like NPAIRS, which evaluate pipelines based on prediction accuracy (P) and spatial reproducibility (R) to select the best pipeline for a specific dataset or even individual task runs [61] [62].
FAQ: How can I be sure my optimized pipeline is more reliable and not just overfitting my data?
A valid concern, as overfitting leads to results that cannot be replicated.
- Root Cause: Overfitting occurs when a pipeline is tuned to the noise or unique artifacts of a specific dataset rather than the neural signal of interest.
- Diagnosis Steps:
- Solution: A robust pipeline should simultaneously minimize spurious test-retest discrepancies while remaining sensitive to meaningful individual differences and experimental effects [5]. The table below shows key criteria for trustworthy pipelines from a systematic evaluation.
Table 1: Multi-Criteria Framework for Evaluating Pipeline Trustworthiness [5]
| Criterion | What It Measures | Why It Matters |
|---|---|---|
| Test-Retest Reliability | Consistency of network topology across repeated scans of the same individual. | Fundamental for any subsequent analysis of individual differences. |
| Sensitivity to Individual Differences | Ability to detect meaningful inter-subject variability. | Ensures the pipeline can correlate brain function with behavior or traits. |
| Sensitivity to Experimental Effects | Ability to detect changes due to a task, condition, or intervention. | Crucial for drawing valid conclusions about experimental manipulations. |
| Robustness to Motion | Minimization of motion-induced confounds in the results. | Reduces the risk of false positives driven by artifact rather than neural signal. |
FAQ: My functional connectivity results change drastically with different analysis choices. How do I choose?
This reflects the "combinatorial explosion" problem in neuroimaging, where numerous analysis choices can lead to vastly different conclusions [5].
- Root Cause: Key decisions in constructing functional brain networks—such as the brain parcellation used to define nodes, the metric for defining edges, and whether to use Global Signal Regression (GSR)—profoundly impact the final results [5].
- Diagnosis Steps:
- Systematically document every choice in your network construction pipeline.
- Check if your results hold across a few different, well-justified parcellation schemes.
- Solution: Do not rely on a single, arbitrarily chosen pipeline. Refer to systematic evaluations that test pipelines against multiple criteria. For functional connectomics, pipelines that satisfy all the criteria in Table 1 across different datasets have been identified and are recommended for use [5].
Experimental Protocols for Reliability Assessment
Protocol 1: Evaluating Pipeline Optimization Using the NPAIRS Framework
This methodology is used to identify preprocessing pipelines that maximize signal detection for a specific study cohort or task [61] [62].
- Data Input: Acquire task-based fMRI data (e.g., block-design tasks). It is advantageous to have data from two independent runs, either between subjects or within-subject test-retest sessions.
- Pipeline Generation: Define a set of candidate preprocessing pipelines that systematically vary key steps, such as:
- Motion correction parameters.
- Physiological noise correction methods (e.g., RETROICOR, data-driven component models).
- High-pass filtering strategies.
- Spatial smoothing kernels.
- Cross-Validation: For each pipeline, apply the NPAIRS framework, which involves:
- Splitting the dataset into multiple training and test sets.
- For each split, fitting a model (e.g., a linear discriminant analysis) on the training set and using it to predict the test set labels.
- Metric Calculation: Compute the two primary NPAIRS metrics for each pipeline [62]:
- Prediction Accuracy (P): The cross-validated accuracy of the model in predicting the task condition.
- Spatial Reproducibility (R): The spatial overlap of the brain activation maps derived from the independent training and test splits.
- Pipeline Selection: The optimal pipeline is the one that achieves the best balance of high prediction accuracy and high spatial reproducibility on the (P,R) plane.
- Independent Validation: Validate the chosen pipeline by measuring the overlap of active brain voxels between the independently-optimized test runs (between-subject or test-retest) [61].
Protocol 2: Systematic Evaluation of Functional Connectomics Pipelines
This protocol outlines a comprehensive, multi-dataset strategy for identifying robust pipelines for functional brain network construction [5].
- Pipeline Construction: Systematically combine different options at each step of the network construction process to generate a large set of candidate pipelines (e.g., 768 pipelines). Key steps include:
- Global Signal Processing: With or without GSR.
- Parcellation: Use various brain atlases (anatomical, functional, multimodal) with different node counts.
- Edge Definition: Pearson correlation or mutual information between node time-series.
- Edge Filtering: Apply different thresholds (density-based, weight-based, data-driven).
- Network Type: Use binary or weighted networks.
- Multi-Criteria Evaluation: Evaluate each pipeline across several independent test-retest datasets (spanning short- and long-term delays) using the following criteria:
- Test-Retest Reliability: Use the Portrait Divergence (PDiv) measure to quantify the dissimilarity between networks from the same individual across sessions. Optimal pipelines minimize this spurious discrepancy [5].
- Biological Sensitivity: Ensure the pipeline is sensitive to individual differences and experimental effects (e.g., a pharmacological intervention).
- Robustness to Motion: The pipeline should minimize the influence of head motion.
- Generalizability Check: Require that optimal pipelines perform well on an entirely independent dataset acquired with different scanning parameters and preprocessed with a different denoising method [5].
- Result Documentation: Provide a full breakdown of each pipeline's performance across all criteria and datasets to inform best practices.
Evaluating Pipeline Trustworthiness
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Tools for Neuroimaging Pipeline Optimization Research
| Tool / Resource | Type | Primary Function |
|---|---|---|
| NPAIRS Framework [61] [62] | Analytical Framework | Provides cross-validated metrics (Prediction Accuracy, Spatial Reproducibility) to quantitatively evaluate and optimize preprocessing pipelines without a ground truth. |
| Portrait Divergence (PDiv) [5] | Metric | An information-theoretic measure that quantifies dissimilarity between whole-network topologies, used for assessing test-retest reliability. |
| FreeSurfer [63] | Software Tool | A widely used suite for automated cortical surface-based and subcortical volume-based analysis of structural MRI data, calculating metrics like cortical thickness and volume. |
| Global Signal Regression (GSR) [5] | Preprocessing Technique | A controversial but impactful step for functional connectivity analysis; its use must be carefully considered and reported. |
| Anatomical CompCor / FIX-ICA [5] | Noise Reduction Method | Data-driven denoising methods used to remove physiological and other nuisance signals from fMRI data. |
From Problem to Solution
Frequently Asked Questions (FAQs)
Resource Allocation and Scheduling
Q1: How can I optimize my resource allocation to reduce job completion time without significantly increasing costs?
A multi-algorithm optimization strategy is recommended for balancing time and cost. Research demonstrates that using metaheuristic algorithms like Genetic Algorithms (GA) and Particle Swarm Optimization (PSO) can yield significant improvements. You can implement the following methodology [64]:
- Decompose Tasks: Break down your primary neuroimaging pipeline tasks (e.g., preprocessing, normalization, statistical analysis) into smaller, manageable sub-tasks.
- Define Options: For each sub-task, identify different computational methods (e.g., different software tools, CPU vs. GPU processing) with associated time and cost estimates.
- Apply Optimization: Use a GA or PSO to explore the solution space. The fitness function should minimize total project duration and cost while satisfying resource constraints.
Experimental results show that this approach can achieve a 7% reduction in total costs and a 20% reduction in project duration [64]. The following table summarizes the performance of two optimization algorithms.
Table 1: Performance Comparison of Metaheuristic Algorithms for Time-Cost Trade-Off (TCT) Optimization [64]
| Optimization Algorithm | Reduction in Direct Costs | Reduction in Indirect Costs | Reduction in Total Project Duration |
|---|---|---|---|
| Genetic Algorithm (GA) | ~3.25% | 20% | Information Missing |
| Particle Swarm Optimization (PSO) | 4% | Comparable to GA | 20% |
Q2: My HPC jobs are frequently interrupted. What strategies can I use to ensure completion while managing costs?
For long-running simulations and data-processing jobs, use automated checkpointing and job recovery techniques. This is particularly effective when using lower-cost, interruptible cloud instances (e.g., AWS Spot Instances) to achieve cost savings compared to On-Demand pricing [65].
- Implementation Protocol:
- Checkpointing: Design your neuroimaging pipeline to periodically save its state (checkpoints) to persistent, high-performance storage (e.g., an FSx for Lustre filesystem).
- Job Navigator & Automation: Implement automation scripts that monitor job status. Upon detecting an interruption, the script should automatically resubmit the job, which then restarts from the last saved checkpoint.
- Orchestration: Use workflow management tools like AWS Batch or similar job schedulers that can be configured with checkpoint-restore capabilities [65]. This strategy allows you to leverage cost-effective resources without sacrificing the reliability of your long-running neuroimaging experiments.
Data Processing and Storage
Q3: The reliability of my fMRI connectivity results varies greatly with different processing pipelines. How can I choose a robust pipeline?
The choice of data-processing pipeline has a dramatic impact on the reliability and validity of functional connectomics results. A systematic evaluation of 768 pipelines recommends selecting those that minimize motion confounds and spurious test-retest discrepancies while remaining sensitive to inter-subject differences [5].
- Experimental Protocol for Pipeline Selection:
- Criterion: Seek pipelines that minimize "Portrait Divergence" (PDiv), an information-theoretic measure of network topology dissimilarity, between test and retest scans of the same individual [5].
- Data Handling: Evaluate your pipeline on data both with and without Global Signal Regression (GSR), as this preprocessing step is controversial and significantly impacts outcomes [5].
- Node Definition: Use a parcellation scheme based on multimodal structural and functional MRI features. Parcellations with approximately 200-300 nodes often provide a good balance between granularity and reliability [5].
- Edge Definition & Filtering: For edge definition, Pearson correlation is a common and reliable start. For filtering, avoid arbitrary thresholds; instead, use data-driven methods like Efficiency Cost Optimisation (ECO) or retain a pre-specified density of edges (e.g., 10%) [5].
Q4: I am running out of storage for large neuroimaging datasets. What are my options for scalable, high-performance storage?
Modern HPC storage solutions are designed to meet the demands of large-scale AI and neuroimaging workloads. Key solutions and their benefits are summarized below.
Table 2: High-Performance Storage Solutions for Neuroimaging Data [66]
| Storage Solution | Key Feature | Performance / Capacity | Benefit for Neuroimaging Research |
|---|---|---|---|
| IBM Storage Scale System 6000 | Support for QLC flash storage | 47 Petabytes per rack [66] | Cost-effective high-density flash for AI training and data-intensive workloads. |
| Pure Storage FlashBlade//EXA | Massively parallel processing | Performance >10 TB/s in a single namespace [66] | Eliminates metadata bottlenecks for massive AI datasets without manual tuning. |
| DDN Sovereign AI Blueprints | Validated, production-ready architecture | Enables >99% GPU utilization [66] | Provides a repeatable, secure framework for national- or enterprise-scale AI data. |
| Sandisk UltraQLC 256TB NVMe SSD | Purpose-built for fast, intelligent data lakes | 256TB capacity (Available H1 2026) [66] | Scales performance and efficiency for AI-driven, data-intensive environments. |
Cost Management and Optimization
Q5: What are the most effective strategies for controlling cloud HPC costs for neuroimaging research?
Effective cost control requires a multi-faceted approach focusing on architectural choices and operational practices.
- Adopt Sustainable Architectures: Follow the AWS Well-Architected Framework’s Sustainability Pillar, which often aligns with cost reduction. This includes using Graviton-based instances for better performance-per-watt and architecting energy-efficient workloads [65].
- Leverage Managed Services: Use managed services like AWS Parallel Computing Service (PCS) or AWS Batch to automate cluster and job management. This reduces the operational overhead and helps optimize resource utilization, preventing over-provisioning [65].
- Implement Operational Dashboards: Go beyond the standard cloud console. Build custom operational dashboards using service events and custom metrics (e.g., with AWS Batch) to monitor workload efficiency and identify cost anomalies in real-time [65].
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Tools for HPC-Enabled Neuroimaging
| Item / Solution | Function / Role in the Research Pipeline |
|---|---|
| Genetic Algorithm (GA) & Particle Swarm Optimization (PSO) | Metaheuristic algorithms for solving complex time-cost-resource trade-off problems in project scheduling [64]. |
| AWS Parallel Computing Service (PCS) | A managed service that automates the creation and management of HPC clusters using the Slurm scheduler, reducing setup complexity [65]. |
| FSx for Lustre | A high-performance file system optimized for fast processing of large datasets, commonly used in HPC for scratch storage [65]. |
| Elastic Fabric Adapter (EFA) | A network interface for Amazon EC2 instances that enables low-latency, scalable inter-node communication, crucial for tightly-coupled simulations [65]. |
| fMRI Processing Pipelines (e.g., FSL, fMRIPrep) | Standardized software suites for automating the preprocessing and analysis of functional MRI data, improving reproducibility [5]. |
| Global Signal Regression (GSR) | A controversial preprocessing step for fMRI data that can improve the detection of biological signals but may also remove neural signals of interest [5]. |
| Portrait Divergence (PDiv) | An information-theoretic metric used to quantify the dissimilarity between entire network topologies, crucial for assessing pipeline reliability [5]. |
Experimental Protocols & Workflows
Workflow 1: Protocol for Evaluating fMRI Pipeline Reliability
This protocol is based on a systematic framework for evaluating the reliability of functional connectomics pipelines [5].
- Data Acquisition: Acquire test-retest resting-state fMRI (rs-fMRI) datasets. For robust results, use datasets with different intervals (e.g., within-session, 2-4 weeks, 5-16 months) and from different sources (e.g., HCP).
- Data Preprocessing: Preprocess the data using a standardized denoising method (e.g., anatomical CompCor or FIX-ICA). Create two versions of the preprocessed data: one with and one without Global Signal Regression (GSR).
- Pipeline Construction: Systematically combine different network construction steps to create a large set of candidate pipelines. Key steps include:
- Node Definition: Apply multiple brain parcellations (anatomical, functional, multimodal) at different resolutions (100, 200, 300-400 nodes).
- Edge Definition: Calculate connections between nodes using Pearson correlation or mutual information.
- Network Filtering: Apply various filtering strategies (e.g., proportional thresholding, minimum weight thresholding, data-driven methods like ECO).
- Network Type: Generate both binary and weighted networks.
- Reliability Assessment: For each pipeline, calculate the Portrait Divergence (PDiv) between test and retest scans of the same individual. Lower PDiv indicates higher reliability.
- Criterion Validation: Validate reliable pipelines by ensuring they are also sensitive to individual differences and experimental effects of interest (e.g., pharmacological interventions).
Workflow 2: Protocol for Optimizing Computational Trade-offs
This protocol outlines a method for optimizing time and cost in a computational project, adapted from construction management research [64].
- Project Decomposition: Break down your primary research goal (e.g., "Process 1000 fMRI datasets") into a set of discrete, sequential activities or tasks that form your pipeline.
- Method Enumeration: For each activity, identify multiple construction methods or computational approaches. For example, for the "fMRI Preprocessing" activity, methods could be "Run on CPU nodes," "Run on GPU nodes," or "Use a cloud-native service."
- Parameter Definition: For each activity-method combination, estimate its duration and cost. This creates a search space of possible project execution paths.
- Model Application: Apply a metaheuristic optimization model (e.g., Genetic Algorithm or Particle Swarm Optimization). The model's objective is to find the combination of methods that minimizes total project duration and cost, subject to resource constraints.
- Schedule Generation: The output of the model is an optimized project schedule, specifying which method to use for each activity and its start time, providing a clear blueprint for efficient resource execution.
Workflow Visualization
Diagram 1: fMRI Pipeline Reliability
Diagram 2: HPC Resource Optimization
Best Practices for Resource Management in CPU vs. GPU Computing Environments
Troubleshooting Guides
Guide 1: Resolving Low GPU Utilization in Neuroimaging Pipelines
Problem: Your machine learning pipeline for neuroimaging analysis (e.g., using fMRI or fNIRS data) is running slowly, and system monitors show that GPU utilization is consistently low (e.g., below 30%), while the CPU appears highly active [67].
Diagnosis: This imbalance often indicates a CPU-to-GPU bottleneck. The CPU is unable to prepare and feed data to the GPU fast enough, leaving the expensive GPU resource idle for significant periods. This is a common challenge in data-intensive neuroimaging workflows [67].
Solution Steps:
- Profile Your Pipeline: Use profiling tools like NVIDIA Nsight Systems or PyTorch Profiler to identify the exact operations where delays occur. Look for long data loading, preprocessing, or CPU-bound transformation steps [68].
- Optimize Data Loading and Preprocessing:
- Implement Asynchronous Data Loading: Use data loaders that pre-fetch the next batch while the current batch is being processed on the GPU [67].
- Preload and Cache Data: Cache frequently accessed datasets or preprocessed data in GPU memory or high-speed storage to minimize disk I/O latency [67].
- Offload to GPU: Move suitable data augmentation operations (e.g., adding Gaussian noise) to the GPU using CUDA or framework-specific methods to reduce CPU load [67] [68].
- Tune Batch Sizes: Experiment with increasing the batch size to fully utilize GPU memory and parallel compute units. If memory is constrained, use gradient accumulation to simulate a larger effective batch size [67].
- Review Model and Operations: Ensure that the model architecture and operations are well-suited for GPU execution. Models with high arithmetic intensity and parallelizable structure maximize GPU throughput [67].
Guide 2: Managing Heterogeneous CPU-GPU Clusters for Reproducible Research
Problem: Neuroimaging experiments produce inconsistent results when run on different nodes within a computing cluster, potentially compromising the reliability of your research findings [56].
Diagnosis: Cluster nodes likely have different hardware configurations (e.g., different CPU architectures, GPU models, or memory sizes). Without proper resource specification and isolation, workloads may be scheduled on nodes with insufficient or incompatible hardware [69] [70].
Solution Steps:
- Implement Node Labeling and Discovery:
- Use Node Affinity and Resource Requests:
- In your pod specifications, use
nodeAffinityrules to ensure pods are scheduled only on nodes that meet the hardware requirements for your pipeline [69]. - Precisely specify resource
requestsandlimitsfor both CPU and GPU in your workload definitions. For GPUs, the request must equal the limit [69] [70]. Example Pod Spec Snippet:
- In your pod specifications, use
- Isolate Workloads with Taints and Tolerations: Apply taints (e.g.,
nvidia.com/gpu=research:NoSchedule) to specialized GPU nodes. Only workloads with the corresponding toleration will be scheduled, preventing contention from non-GPU jobs [70].
Frequently Asked Questions (FAQs)
Q1: Why is our neuroimaging pipeline's performance highly variable, even when using the same dataset and algorithm?
A1: Performance variability in complex pipelines can stem from multiple sources [56]:
- Hardware-Level Variability: Differences in CPU/GPU performance, memory bandwidth, and storage I/O can significantly impact runtimes [69] [67].
- Software and Pipeline Configuration: The choice of preprocessing steps, hyperparameters, and analysis methods can greatly influence both performance and results. Studies show that even experienced researchers choose diverse, justifiable analysis pipelines for the same neuroimaging data, leading to variability in outcomes [56].
- System Load: Contention for shared resources (CPU, memory, network) in multi-tenant environments can cause performance fluctuations.
Mitigation Strategy: For reproducible research, standardize the computing environment using containers (e.g., Docker, Singularity) and explicitly define all resource requests and limits in your orchestration tool (e.g., Kubernetes). Document all pipeline components and parameters in detail [56].
Q2: When should we prioritize CPU over GPU optimization in our computational experiments?
A2: Focus on CPU optimization in these scenarios [67] [68]:
- Data Preprocessing and I/O-Bound Tasks: When your workflow involves extensive data loading, feature extraction, or data augmentation that cannot be efficiently parallelized on a GPU.
- Small-Scale Models or Data: If the model or dataset is small, the overhead of transferring data to the GPU may outweigh the computational benefits.
- Complex Control Flow: Algorithms with significant sequential dependencies or branches are often better suited for CPUs. Prioritize GPU optimization for large-scale, compute-intensive, and highly parallelizable tasks like training deep learning models on large neuroimaging datasets (e.g., 3D convolutional networks) [68].
Q3: Our deep learning models for neuroimaging are running out of GPU memory. What are our options besides getting a larger GPU?
A3: Several techniques can reduce GPU memory footprint [67]:
- Enable Mixed Precision Training: Use 16-bit floating-point numbers (FP16) alongside 32-bit (FP32) to halve memory usage and potentially increase training speed on supported GPUs.
- Implement Gradient Accumulation: Process smaller batches sequentially and accumulate gradients over several steps before updating model weights, effectively simulating a larger batch size.
- Use Gradient Checkpointing: Trade compute for memory by selectively re-computing intermediate activations during the backward pass instead of storing them all.
- Apply Memory Optimization Frameworks: Leverage features like PyTorch's
memory_efficientmode or TensorFlow'stf.functionwith experimental compilation options.
Performance Comparison: CPU vs. GPU
The table below summarizes typical performance characteristics of CPUs and GPUs for tasks relevant to neuroimaging pipeline reliability assessment. This data is synthesized from benchmark rankings and industry observations [71] [67] [72].
Table 1: Performance and Resource Management Characteristics for Neuroimaging Workloads
| Feature | CPU (Central Processing Unit) | GPU (Graphics Processing Unit) |
|---|---|---|
| Optimal Workload Type | Sequential processing, complex control logic, I/O-bound tasks, small-batch inference [68] | Massively parallel processing, compute-intensive tasks, large-matrix operations [68] |
| Typical Neuroimaging Use Case | Data preprocessing, feature normalization, running statistical tests, small-cohort classical ML [44] | Training deep learning models (CNNs, Transformers), large-scale image processing, inference on large datasets [67] |
| Memory Bandwidth | Lower (e.g., ~50-100 GB/s for system RAM) | Very High (e.g., ~500-1800 GB/s for GPU VRAM) [73] |
| Parallel Threads | Fewer concurrent threads (e.g., tens to hundreds) | Thousands of concurrent, lightweight threads [68] |
| Common Benchmark Performance (Relative %) | Varies by model (see CPU Hierarchy [72]) | Varies by model (see GPU Hierarchy [71]) |
| Key Management Consideration | Optimize for latency and single-thread performance. | Optimize for throughput; avoid starvation from data or CPU bottlenecks [67]. |
Experimental Protocol: Resource Utilization Analysis
This protocol provides a methodology for quantitatively assessing the CPU and GPU resource utilization of a neuroimaging machine learning pipeline, similar to studies that evaluate pipeline efficacy on multimodal data [44].
1. Objective: To measure and analyze the compute resource efficiency (CPU and GPU) of a specified neuroimaging classification or analysis pipeline under controlled conditions.
2. Materials and Setup:
- Hardware: A dedicated server node equipped with both a multi-core CPU and a dedicated NVIDIA GPU. Example specifications include:
- Software:
- Operating System: Ubuntu 22.04 LTS.
- Container Runtime: Docker 24.0+.
- Orchestration: Kubernetes (via
minikube) with NVIDIA GPU operator and device plugins installed [69] [70]. - Monitoring Tools: Prometheus and Grafana, configured with
dcgm-exporterfor GPU metrics andnode-exporterfor CPU/memory metrics [70].
3. Procedure: 1. Containerization: Package the neuroimaging pipeline and all its dependencies into a Docker container. 2. Workload Definition: Create a Kubernetes Pod specification file (.yaml) that requests specific CPU and GPU resources, as shown in the troubleshooting guides above. 3. Baseline Execution: Deploy the Pod and run the pipeline on a standard, well-understood neuroimaging dataset (e.g., a public fNIRS or MRI dataset). 4. Metric Collection: During execution, use the monitoring stack to collect time-series data for the following Key Performance Indicators (KPIs) at 1-second intervals: * GPU Utilization (% time compute cores are active) * GPU Memory Utilization (% and GiB) * CPU Utilization (per core and overall %) * System Memory Utilization (GiB) * I/O Wait (% CPU time waiting for I/O) * Pipeline Execution Time (total end-to-end runtime) 5. Iterative Optimization: Repeat steps 3-4 after applying one optimization strategy at a time (e.g., increasing batch size, implementing asynchronous data loading, enabling mixed precision).
4. Data Analysis: * Calculate the average and peak utilization for CPU and GPU. * Identify bottlenecks by correlating periods of low GPU utilization with high CPU utilization or I/O wait times. * Compare the total execution time and cost-effectiveness (performance per watt or per dollar) before and after optimizations.
The Scientist's Toolkit: Research Reagent Solutions
This table lists key computational "reagents" and their functions for building reliable and efficient neuroimaging analysis pipelines.
Table 2: Essential Tools and Solutions for Computational Neuroimaging Research
| Tool / Solution | Function | Relevance to Pipeline Reliability |
|---|---|---|
| Kubernetes with GPU Plugin | Orchestrates containerized workloads across clusters, managing scheduling and resource allocation for both CPU and GPU tasks [69] [70]. | Ensures consistent runtime environment and efficient use of heterogeneous hardware, directly addressing resource management challenges. |
| NVIDIA GPU Operator | Automates the management of all NVIDIA software components (drivers, container runtime, device plugin) needed to provision GPUs in Kubernetes [70]. | Simplifies cluster setup and maintenance, reducing configuration drift and improving the reproducibility of the computing environment. |
| Node Feature Discovery (NFD) | Automatically detects hardware features and capabilities on cluster nodes and labels them accordingly [69] [70]. | Enables precise workload scheduling by ensuring pipelines land on nodes with the required CPU/GPU capabilities. |
| NVIDIA DCGM Exporter | A metrics exporter that monitors GPU performance and health, providing data for tools like Prometheus [70]. | Allows for continuous monitoring of GPU utilization, a critical KPI for identifying bottlenecks and ensuring resource efficiency [67]. |
| Container Images (Docker) | Pre-packaged, versioned environments containing the entire software stack (OS, libraries, code) for a pipeline [56]. | The foundation for reproducibility, guaranteeing that the same software versions and dependencies are used in every execution, from development to production. |
Workflow and Relationship Diagrams
Diagram 1: Troubleshooting Low GPU Utilization
Diagram 2: APOD Development Cycle for GPU Applications [68]
Metrics and Validation Frameworks: Assessing Reliability and Comparative Pipeline Performance
In neuroimaging research, assessing the reliability of measurement pipelines is fundamental for producing valid, reproducible results. Two core metrics used to evaluate reliability are the Intra-Class Correlation Coefficient (ICC) and the Coefficient of Variation (CV). While sometimes mentioned interchangeably, they answer distinctly different scientific questions. The CV assesses the precision of a measurement, whereas the ICC assesses its ability to discriminate between individuals. Understanding this difference is critical for choosing the right metric for your experiment and correctly interpreting your results [75].
This guide provides troubleshooting advice and FAQs to help you navigate common challenges in reliability assessment for neuroimaging pipelines.
Quick-Reference Comparison Table
The table below summarizes the core differences between ICC and CV.
| Feature | Intra-Class Correlation (ICC) | Coefficient of Variation (CV) |
|---|---|---|
| Core Question | Can the measurement reliably differentiate between participants? [75] [76] | How precise is the measurement for a single participant or phantom? [75] |
| Statistical Definition | Ratio of between-subject variance to total variance: ICC = σ²B / (σ²B + σ²W) [75] | Ratio of standard deviation to the mean: CV = σ / μ [77] [78] |
| Interpretation | Proportion of total variance due to between-subject differences [79] [80] | Normalized measure of dispersion around the mean [77] |
| Scale | Dimensionless, ranging from 0 to 1 (for common formulations) [81] [80] | Dimensionless, often expressed as a percentage (%); ranges from 0 to ∞ [77] |
| Primary Context | Assessing individual differences in human studies [75] [76] | Assessing precision in phantom scans or single-subject repeated measurements [75] [82] |
Frequently Asked Questions (FAQs)
Q1: I need to show that my neuroimaging biomarker can tell participants apart. Which metric should I use?
You should use the Intra-Class Correlation (ICC).
- Reasoning: The ICC is specifically designed for this purpose. It quantifies how well your measurement can distinguish between different participants by comparing the variability between subjects to the total variability in your data [75] [76]. A high ICC indicates that the differences in your data are driven more by genuine differences between people than by measurement noise.
Q2: My goal is to optimize an MRI sequence for the most consistent measurements in a single phantom. What is the best metric?
You should use the Coefficient of Variation (CV).
- Reasoning: In this context, you are not interested in individual differences but in the pure precision of the scanner itself. The CV measures the variability of repeated measurements around their own mean. A lower CV indicates higher precision and less measurement noise [75] [82].
Q3: I calculated both, and my CV is low (good precision), but my ICC is also low (poor discrimination). How is this possible?
This is a common and understandable scenario. The relationship between the metrics is clarified in the diagram below.
This situation occurs when your measurement instrument is very stable (low within-subject variance, leading to a low CV), but the participants in your study are all very similar to each other on the trait you are measuring (low between-subject variance). Since the ICC is the ratio of between-subject variance to total variance, if the between-subject variance is small, the ICC will be low regardless of good precision [75].
Q4: I see different forms of ICC (e.g., ICC(2,1), ICC(3,1)). Which one should I use for my test-retest study?
The choice of ICC form is critical and depends on your experimental design. The flowchart below outlines the decision process.
For a typical test-retest reliability study in neuroimaging where you use the same scanner to measure all participants and wish to generalize your findings to other scanners of the same type, the Two-Way Random Effects Model (often corresponding to ICC(2,1) for a single measurement) is usually the most appropriate choice [81].
Q5: What are the benchmark values for interpreting ICC and CV?
ICC Interpretation Guidelines
The following table provides general guidelines for interpreting ICC values in a research context [81].
| ICC Value | Interpretation |
|---|---|
| < 0.50 | Poor reliability |
| 0.50 - 0.75 | Moderate reliability |
| 0.75 - 0.90 | Good reliability |
| > 0.90 | Excellent reliability |
CV Interpretation
For CV, there are no universal benchmarks because "good" precision is highly field- and measurement-specific. The evaluation is often based on comparison with established protocols or the requirements of your specific study. A lower CV is always better for precision, and values should ideally be well below 10% [77] [78].
Troubleshooting Guide: Solving Common Reliability Problems
Problem: Unusually Low or Negative ICC Values
- Symptom: Your calculated ICC is below 0.5 or even negative.
- Potential Causes & Solutions:
- Insufficient Between-Subject Variance: Your sample may be too homogeneous. Solution: Recalculate ICC with a more diverse participant pool, if possible.
- High Measurement Noise: Poor data quality or an unstable pipeline inflates within-subject variance. Solution: Check data quality, optimize preprocessing steps (e.g., motion correction), and consider if a more robust imaging sequence is needed.
- Incorrect ICC Model: You may have used a model that doesn't fit your experimental design. Solution: Re-run your analysis using the correct ICC form (see FAQ #4 and [81]).
- True Lack of Reliability: The biological signal or measurement may genuinely not be reproducible. Solution: The analysis is working correctly and revealing a true limitation of the measure.
Problem: High CV Values Across All Subjects
- Symptom: The measurement precision is consistently poor for all participants or phantoms.
- Potential Causes & Solutions:
- Scanner Instability: The MRI system itself may have technical issues or require calibration. Solution: Perform regular quality assurance (QA) with a phantom to monitor scanner stability.
- Poor Protocol Design: The imaging sequence parameters (e.g., low resolution, low signal-to-noise ratio) may be suboptimal. Solution: Work with an MR physicist to optimize the acquisition protocol for the specific biomarker.
- Data Processing Pipeline: Certain preprocessing steps may introduce unnecessary variance. Solution: Perform a systematic review of your pipeline. Test the impact of different smoothing kernels, as this can significantly affect reliability [82].
Essential Research Reagent Solutions
The table below lists key tools and concepts essential for conducting reliability analysis in neuroimaging.
| Item | Function in Reliability Analysis |
|---|---|
| Statistical Software (AFNI, SPSS, R) | Provides built-in functions (e.g., 3dICC in AFNI [79]) for calculating ICC and CV from ANOVA or mixed-effects models. |
| ANOVA / Linear Mixed-Effects (LME) Models | The statistical framework used to decompose variance components (between-subject, within-subject) required for calculating ICC [79] [80]. |
| ICC Form Selection Guide | A decision tree (like the one in this article) to select the correct ICC model (one-way, two-way random, two-way mixed) for a given experimental design [81]. |
| Phantom | A standardized object scanned repeatedly to assess scanner precision and stability using the CV, independent of biological variance [75]. |
Frequently Asked Questions (FAQs)
Q1: What is the core difference between Intra-Class Correlation (ICC) and Coefficient of Variation (CV) in reliability assessment?
ICC and CV represent fundamentally different conceptions of reliability. ICC expresses how well a measurement instrument can detect between-person differences and is calculated as the ratio of variance-between to total variance. In contrast, CV evaluates the absolute precision of measuring a single object (e.g., a phantom or participant) and is defined as the ratio of within-object variability to the mean value [83] [75].
Q2: What types of measurement error can ICED help identify in neuroimaging studies?
ICED can decompose multiple orthogonal sources of measurement error associated with different experimental characteristics [83]:
- Session-to-session variability: Effects of different scanning sessions
- Day-to-day variability: Effects of scanning on different days
- Site-related variability: Effects of different scanners or scanning sites (in multi-center studies)
- Run-to-run variability: Effects of different acquisition runs within the same session
- Complex nested structures: For example, runs nested within sessions, which are in turn nested within days [83]
Q3: How can ICED improve the design of future neuroimaging studies?
By quantifying the magnitude of different error components, ICED enables researchers to [83]:
- Identify the largest sources of measurement error to target for improvement
- Optimize study designs to control for major error sources
- Make informed decisions about the number of repeated measurements needed
- Improve generalizability of findings by accounting for multiple variance components
Q4: What are the advantages of using ICED over traditional reliability measures?
Unlike traditional approaches that provide a single reliability estimate, ICED offers [83]:
- Detailed variance decomposition: Separates total measurement error into specific components
- Design flexibility: Can model complex nested experimental structures
- Visual representation: Allows creation of path diagrams to represent error structures
- Informed decision-making: Provides specific guidance for improving measurement precision
Troubleshooting Common Experimental Issues
Problem: Inconsistent reliability estimates across different study designs
Solution: ICED explicitly accounts for the nested structure of your experimental design. When implementing ICED, ensure your model correctly represents the hierarchy of your measurements (e.g., runs within sessions, sessions within days). This prevents biased reliability estimates that occur when these nuances are neglected [83].
Problem: Inability to determine whether poor reliability stems from participant variability or measurement inconsistency
Solution: Use ICED's variance decomposition to distinguish between these sources. The method separates true between-person variance (signal) from various within-person error components (noise), allowing you to identify whether reliability limitations come from insufficient individual differences or excessive measurement error [83].
Problem: Uncertainty about how many repeated measurements are needed for adequate reliability
Solution: After implementing ICED, use the estimated variance components to conduct power analysis for future studies. The method provides specific information about the relative magnitude of different error sources, enabling optimized design decisions about the number of sessions, days, or runs needed to achieve target reliability levels [83].
Experimental Protocols & Methodologies
ICED Implementation Workflow
Key Variance Components in Neuroimaging Reliability Assessment
Table: Quantitative Framework for Interpreting ICED Results in Neuroimaging
| Variance Component | Definition | Interpretation | Typical Impact on Reliability |
|---|---|---|---|
| Between-Person Variance | Differences in the measured construct between individuals | Represents the "signal" for individual differences research | Higher values improve reliability for individual differences studies |
| Within-Person Variance | Fluctuations in measurements within the same individual | Consists of multiple decomposable error sources | Higher values decrease reliability |
| Session-Level Variance | Variability introduced by different scanning sessions | Impacts longitudinal studies tracking change over time | Particularly problematic for test-retest reliability |
| Day-Level Variance | Variability between scanning days | Reflects day-to-day biological and technical fluctuations | Affects studies with multiple day designs |
| Site-Level Variance | Variability between different scanning sites | Critical for multi-center clinical trials | Can introduce systematic bias in large-scale studies |
Protocol 1: Basic ICED Implementation for Test-Retest Reliability
Purpose: Decompose measurement error into session-level and participant-level components in a simple test-retest design.
Procedure:
- Collect repeated measurements from the same participants across multiple sessions
- Specify a structural equation model with orthogonal error components
- Define the nested structure of your measurements (e.g., sessions within participants)
- Estimate variance components for each level of the hierarchy
- Calculate ICC using the formula: ICC = σ²-between-persons / (σ²-between-persons + σ²-error) [83] [75]
Interpretation: A high session-level variance component suggests that repositioning or day-to-day fluctuations significantly impact reliability, guiding improvements in protocol standardization.
Protocol 2: Advanced ICED for Multi-Site Studies
Purpose: Quantify site-specific variance in multi-center neuroimaging studies.
Procedure:
- Collect data using the same protocol across multiple scanning sites
- Implement a cross-classified model that accounts for participants nested within sites
- Include session-level repeated measurements within each site
- Estimate variance components for participant, site, session, and residual error
- Calculate generalizability coefficients for different study designs [83]
Interpretation: Significant site-level variance indicates need for improved standardization across sites or inclusion of site as a covariate in analyses.
The Scientist's Toolkit: Essential Research Materials
Table: Key Methodological Components for ICED Implementation
| Component | Function | Implementation Considerations |
|---|---|---|
| Structural Equation Modeling Software | Estimates variance components and model parameters | Use established SEM packages (e.g., lavaan, Mplus) with appropriate estimation methods for neuroimaging data [84] |
| Repeated-Measures Neuroimaging Data | Provides the raw material for variance decomposition | Should include multiple measurements per participant across the error sources of interest (sessions, days, sites) [83] |
| Experimental Design Specification | Defines the nested structure of measurements | Must correctly represent hierarchy (runs in sessions, sessions in days) to avoid biased estimates [83] |
| Data Processing Pipeline | Ensures consistent feature extraction from neuroimages | Standardization critical for minimizing introduced variability; should be identical across all repetitions [84] |
| Computing Resources | Handles computationally intensive SEM estimation | Neuroimaging datasets often require substantial memory and processing power for timely analysis |
Advanced Analytical Framework
Frequently Asked Questions (FAQs)
Q1: What are the primary functional differences between fMRIPrep and DeepPrep for processing neonatal data?
fMRIPrep requires extensions like fMRIPrep Lifespan to handle neonatal and infant data effectively. This involves key adaptations such as using age-specific templates for registration and supporting specialized surface reconstruction methods like M-CRIB-S (for T2-weighted images in infants up to 2 months) and Infant Freesurfer (for infants 4 months to 2 years). These are necessary to address challenges like contrast inversion in structural MRI images and rapid developmental changes in brain size and folding [85]. The capability of DeepPrep in this specific domain is not detailed in the provided search results.
Q2: How can I validate the reliability of my pipeline's output for a test-retest study? A robust methodological framework for reliability assessment involves calculating the Portrait Divergence (PDiv). This information-theoretic measure quantifies the dissimilarity between two networks by comparing their full connectivity structure across all scales, from local connections to global topology. A lower PDiv value between two scans of the same subject indicates higher test-retest reliability. This method was successfully applied in a large-scale evaluation of 768 fMRI processing pipelines [5].
Q3: What are the critical choices in a pipeline that most significantly impact network topology? A systematic evaluation highlights that the choice of global signal regression (GSR), brain parcellation scheme (defining network nodes), and edge definition/filtering method are among the most influential steps. The suitability of a specific combination is highly dependent on the research goal, as a pipeline that minimizes motion confounds might simultaneously reduce sensitivity to a desired experimental effect [5].
Q4: My pipeline failed during surface reconstruction for an infant dataset. What should I check?
When using fMRIPrep Lifespan, first verify the age of the participant and the available anatomical images. The pipeline uses an "auto" option to select the best surface reconstruction method. For failures in very young infants (≤3 months), ensure a high-quality T2-weighted image is provided and consider using a precomputed segmentation (e.g., from BIBSnet) as input for the M-CRIB-S method, which requires high-precision segmentation for successful surface generation [85].
Q5: Can I incorporate precomputed derivatives into my fMRIPrep workflow?
Yes, recent versions of fMRIPrep (e.g., 25.0.0+) have substantially improved support for precomputed derivatives. You can specify multiple precomputed directories (e.g., for anatomical and functional processing) using the --derivatives flag. The pipeline will use these inputs to skip corresponding processing steps, which can save significant computation time [86].
Troubleshooting Guides
Issue: Poor Functional-to-Anatomical Registration in Infant Data Problem: Alignment of functional BOLD images to the anatomical scan fails or is inaccurate for participants in the first years of life. Solution:
- Use an age-specific workflow: Employ
fMRIPrep Lifespan, which is explicitly optimized for this age range [85]. - Leverage T2-weighted images: If available, ensure the T2w image is provided. The pipeline can use it for better coregistration, as T1-weighted images often have poor tissue contrast in very young infants [85].
- Check template choice: The pipeline automatically uses the best-match, age-specific template for spatial normalization. Manually verifying the template used in the report can help diagnose issues [85].
Issue: High Test-Retest Variability in Functional Connectomes Problem: Network topology metrics derived from your pipeline show low consistency across repeated scans of the same individual. Solution:
- Re-evaluate your pipeline: Refer to the systematic evaluation by [5]. Their findings can guide you toward pipeline choices that maximize reliability.
- Adopt a recommended pipeline: The study identified a set of optimal pipelines that consistently minimized spurious test-retest discrepancies across multiple datasets and time intervals. Their interactive Pipeline Selection Tool can be consulted for specific recommendations based on your criteria (e.g., with or without GSR) [5].
- Focus on topology: Use a holistic measure like Portrait Divergence to assess reliability, as it is more comprehensive than comparing individual graph metrics [5].
Issue: fMRIPrep Crashes During Brain Extraction Problem: The structural processing workflow fails at the brain extraction step. Solution:
- Update your version: If using an older version of fMRIPrep, upgrade to the latest (e.g., 25.0.0+). The brain extraction algorithm was modified in recent releases to more closely match the
antsBrainExtraction.shworkflow from ANTs, which fixed a crash that occurred in rare cases [86]. - Inspect the input data: Manually check the quality of the T1-weighted (and T2-weighted) image for severe artifacts or unusual anatomy that could confuse the algorithm.
Experimental Protocols for Reliability Assessment
Protocol 1: Evaluating Test-Retest Reliability Using Portrait Divergence This protocol measures the consistency of functional network topology across repeated scans [5].
- Dataset: Acquire a test-retest dataset where the same participant is scanned multiple times. The delay between sessions can vary (e.g., minutes, weeks, or months).
- Preprocessing: Process all scans through the pipeline(s) under evaluation (e.g., fMRIPrep).
- Network Construction: Construct a functional brain network for each scan. This involves:
- Parcellation: Apply a brain atlas to define network nodes.
- Edge Definition: Calculate connectivity (e.g., using Pearson correlation) between node time series.
- Filtering: Apply a threshold to retain a specific density of connections.
- Reliability Calculation: For each subject, calculate the Portrait Divergence (PDiv) between every pair of their test and retest networks. Lower PDiv values indicate higher reliability.
Protocol 2: Benchmarking Against a Standardized Pipeline (ABCD-BIDS/HCP) This protocol assesses the similarity of a pipeline's outputs to those from established, high-quality workflows [85].
- Dataset: Use a standardized dataset (e.g., from the Baby Connectome Project or Human Connectome Project).
- Parallel Processing: Process the same dataset through two pipelines: the one being evaluated (e.g., fMRIPrep Lifespan) and the reference pipeline (e.g., ABCD-BIDS or HCP pipelines).
- Output Comparison: Quantitatively compare key derivatives, such as the quality of surface reconstructions, spatial normalization accuracy, and functional data alignment. This can be done via manual expert rating or automated image similarity metrics.
Table 1: fMRIPrep Lifespan Surface Reconstruction Success Rates by Age Group Data derived from a quality control assessment of 30 subjects (1-43 months) from the Baby Connectome Project, processed with fMRIPrep Lifespan. [85]
| Surface Reconstruction Method | Recommended Age Range | Primary Image Contrast | Success Rate / Quality Notes |
|---|---|---|---|
| M-CRIB-S | 0 - 3 months | T2-weighted | High-quality outputs for infants ≤3 months; surpasses Infant Freesurfer in this age group. |
| Infant Freesurfer | 4 months - 2 years | T1-weighted | Successful for all participants in the tested range when used with BIBSNet segmentations. |
| Freesurfer recon-all | ≥ 2 years | T1-weighted | Standard method for older children and adults. |
Table 2: Systematic Pipeline Evaluation Criteria and Performance Summary of key criteria from a large-scale study evaluating 768 fMRI network-construction pipelines. [5]
| Evaluation Criterion | Description | Goal for a Good Pipeline |
|---|---|---|
| Test-Retest Reliability | Minimize spurious topological differences between networks from the same subject scanned multiple times. | Minimize Portrait Divergence. |
| Sensitivity to Individual Differences | Ability to detect consistent topological differences between different individuals. | Maximize reliable inter-subject variance. |
| Sensitivity to Experimental Effects | Ability to detect changes in network topology due to a controlled intervention (e.g., anesthesia). | Maximize effect size for the experimental contrast. |
| Robustness to Motion | Minimize the correlation between network topology differences and subject head motion. | Minimize motion-related confounds. |
The Scientist's Toolkit: Key Research Reagents & Materials
Table 3: Essential Software and Data Resources for Neuroimaging Pipeline Assessment
| Item | Function / Description | Usage in Evaluation |
|---|---|---|
| fMRIPrep / fMRIPrep Lifespan | A robust, standardized pipeline for preprocessing of fMRI data. Can be extended to cover the human lifespan. | The primary software under evaluation for data preprocessing [85] [86]. |
| Portrait Divergence (PDiv) | An information-theoretic metric that quantifies the dissimilarity between two networks based on their full multi-scale topology. | The core metric for assessing test-retest reliability and other topological differences [5]. |
| Test-Retest Datasets | MRI datasets where the same participant is scanned multiple times over short- and long-term intervals. | Provides the ground-truth data for assessing pipeline reliability and stability [5]. |
| Brain Parcellation Atlases | Schemes to divide the brain into distinct regions-of-interest (nodes), e.g., anatomical, functional, or multimodal atlases. | A critical variable in network construction; different atlases significantly impact results [5]. |
| BIBSnet | A deep learning tool for generating brain segmentations in infant MRI data. | Used to provide high-quality, precomputed segmentations for surface reconstruction in fMRIPrep Lifespan [85]. |
Workflow Diagram for Pipeline Evaluation
Neuroimaging Pipeline Evaluation Workflow
fMRIPrep Lifespan Adaptive Processing
Validating Anatomical Parcellation and Functional Connectivity Measures Across Pipelines
Troubleshooting Guides
Guide 1: Addressing Poor Test-Retest Reliability in Functional Connectomics
Problem: The functional brain networks you reconstruct from the same individual show vastly different topologies across repeated scan sessions, making it difficult to study individual differences or clinical outcomes [5].
Investigation & Solution:
| Step | Action | Purpose & Considerations |
|---|---|---|
| 1. Verify Pipeline Components | Document your exact pipeline: parcellation, edge definition, global signal regression (GSR), and filtering method [5]. | Systematic variability arises from specific combinations of choices. Inconsistent parameters between runs cause spurious discrepancies. |
| 2. Evaluate Topological Reliability | Calculate the Portrait Divergence (PDiv) between networks from the same subject across different sessions [5]. | PDiv is an information-theoretic measure that compares whole-network topology, going beyond individual graph properties. |
| 3. Optimize Pipeline Choice | Switch to a pipeline validated for reliability. Optimal pipelines often use a brain parcellation derived from multimodal MRI and define edges using Pearson correlation [5]. | The choice of pipeline can produce replicably misleading results. Using an end-to-end validated pipeline minimizes spurious test-retest differences. |
| 4. Control for Motion | Ensure rigorous motion correction is included in your preprocessing workflow. Re-run preprocessing if necessary [5]. | Motion artifacts are a major source of spurious functional connectivity and unreliable network topology. |
Guide 2: Mitigating Analytical Variability in Task-fMRI Results
Problem: Your task-fMRI results (e.g., activation maps) change significantly when you use different analytical pipelines, threatening the reproducibility of your findings [7].
Investigation & Solution:
| Step | Action | Purpose & Considerations |
|---|---|---|
| 1. Identify Key Variability Drivers | Systematically test the impact of software package, spatial smoothing, and the number of motion parameters in the GLM [7]. | Studies like NARPS found that smoothing and software package are major drivers of variability in final results. |
| 2. Standardize the Computing Environment | Use containerization tools like Docker or NeuroDocker to create a consistent environment for running analyses [7]. | This eliminates variability induced by different operating systems or software versions. |
| 3. Adopt a Multi-Pipeline Approach | If possible, run your analysis through a small set of standard pipelines (e.g., 2-3) and compare the resulting statistic maps [7]. | This helps you understand the robustness of your findings across a controlled part of the pipeline space. |
| 4. Report Pipeline Details Exhaustively | In publications, report all parameters and software versions used, including smoothing kernel size (FWHM) and the exact set of motion regressors [7]. | Detailed reporting is crucial for replication and for understanding the context of your results. |
Guide 3: Resolving Homogeneity-Separation Trade-off in Brain Parcellations
Problem: You are unsure which brain parcellation to use for your analysis, as different parcellations offer different region boundaries and granularities, with no clear "ground truth" available [87].
Investigation & Solution:
| Step | Action | Purpose & Considerations |
|---|---|---|
| 1. Define Your Evaluation Context | Decide on the primary goal of your analysis (e.g., maximizing sensitivity to a clinical contrast, identifying individual differences) [87]. | There is no single "best" parcellation. The optimal parcellation depends on the specific application and scientific question. |
| 2. Quantify Parcellation Quality | Calculate both region homogeneity (similarity of time-series/connectivity within a region) and region separation (dissimilarity between regions) for candidate parcellations [87]. | An effective parcellation should have high values for both. These metrics evaluate the conformity to an ideal parcellation. |
| 3. Assess Reliability | Check the reproducibility of the parcellation across different individuals or different scans from the same individual [87]. | A robust parcellation should show consistent boundaries and regions across subjects and sessions. |
| 4. Perform Context-Based Validation | Test how well each candidate parcellation performs on your specific task (e.g., its power to detect a group difference or correlate with a behavioral measure) [87]. | This teleological approach directly evaluates the parcellation's utility for your research context. |
Frequently Asked Questions (FAQs)
FAQ 1: Pipeline Selection and Validation
Q1: With so many possible analysis pipelines, how can I identify a good one for my functional connectivity study? A1: A good pipeline must balance multiple criteria. It should minimize spurious test-retest differences while remaining sensitive to meaningful biological effects like individual differences or clinical contrasts. Look for pipelines that have been validated end-to-end across multiple independent datasets. Systematic evaluations have shown that pipelines using certain multimodal parcellations and Pearson correlation for edge definition can consistently satisfy these criteria [5].
Q2: How critical is the choice of brain parcellation for my analysis? A2: It is one of the most critical choices. The parcellation defines the nodes of your network, and this definition can significantly impact your analysis outcomes. Parcellations differ in their spatial boundaries, granularity (number of regions), and the algorithm used to create them, all of which influence the resulting functional connectivity estimates [87].
Q3: Should I use Global Signal Regression (GSR) in my pipeline? A3: GSR remains controversial. The best practice is to evaluate your results with and without GSR, as its impact can vary. Furthermore, some network construction pipelines are optimal for GSR-processed data, others for non-GSR data, and a subset performs well in both contexts. You should identify which category your chosen pipeline falls into and report your findings accordingly [5].
FAQ 2: Data and Methodological Challenges
Q4: I am working with a small cohort (e.g., for a rare disease). Can I still rely on machine learning with neuroimaging data? A4: Yes, but with caution. For small-cohort studies, extensive tuning of machine learning pipelines (feature selection, hyperparameter optimization) provides only marginal gains. The emphasis should shift from exhaustive pipeline refinement to addressing data-related limitations. Focus on maximizing information from existing data and, if possible, progressively expanding your cohort size or integrating additional complementary modalities [44].
Q5: What are the most common pitfalls in functional connectivity analysis, and how can I avoid them? A5: Common pitfalls include the common reference problem, low signal-to-noise ratio, volume conduction, and sample size bias. It is crucial to understand the assumptions and limitations of your chosen connectivity metric (e.g., coherence, phase synchronization, Granger causality). Using simulated data to test how these pitfalls affect your specific metric can help you interpret real data more validly [88].
Q6: How do I know if my brain parcellation is of high quality in the absence of a ground truth? A6: In the absence of ground truth, evaluate your parcellation based on established desirable characteristics. The core criteria are Effectiveness (Does it create homogeneous and well-separated regions?) and Reliability (Is it reproducible across subjects and sessions?). Additionally, you can use external information not used to create the parcellation (e.g., task-evoked activation maps or microstructure data) for further validation [87].
Experimental Protocols & Data
Table 1: Key Evaluation Metrics for Pipeline and Parcellation Validation
| Evaluation Goal | Primary Metric(s) | Description & Interpretation | Key References |
|---|---|---|---|
| Network Reliability | Portrait Divergence (PDiv) | An information-theoretic measure quantifying the dissimilarity between two networks' topologies across all scales. Lower values indicate higher reliability. | [5] |
| Parcellation Homogeneity | Pearson Correlation (within region) | Measures the average similarity of BOLD time series or functional connectivity profiles of voxels within the same region. Higher values indicate more homogeneous regions. | [87] |
| Parcellation Separation | Fisher's criterion, Silhouette score | Quantifies how distinct a region is from its neighbors. Higher values indicate clearer boundaries between regions. | [87] |
| Pipeline Sensitivity | Effect Size Detection | The ability of a pipeline to uncover meaningful experimental effects (e.g., group differences) or correlate with behavioral traits. | [5] |
Table 2: Systematic Evaluation of fMRI Pipeline Components
| Pipeline Stage | Common Choices | Impact on Results | Recommendations from Literature |
|---|---|---|---|
| Global Signal Regression | Applied / Omitted | Highly controversial; can remove neural signal and alter correlations. Can reduce motion confounds. | Test pipelines with and without GSR. Some pipelines are optimal for one context or the other [5]. |
| Brain Parcellation | Anatomical vs. Functional; ~100 to ~400 nodes | Defines network nodes. Different parcellations lead to different network topologies and conclusions. | Multimodal parcellations (using both structure and function) often show robust performance [5]. |
| Edge Definition | Pearson Correlation / Mutual Information | Determines how "connection strength" is calculated. | Pearson correlation is widely used and performs well in systematic evaluations [5]. |
| Spatial Smoothing | e.g., 5mm vs. 8mm FWHM | Affects spatial precision and signal-to-noise. A key driver of analytical variability. | The choice significantly impacts final activation maps and should be consistently reported [7]. |
Logical Workflow for Pipeline Validation
Title: Pipeline Validation Workflow
The Scientist's Toolkit
Essential Research Reagents & Solutions
| Item / Solution | Function & Purpose in Validation |
|---|---|
| Test-Retest Datasets | Fundamental for assessing the reliability of a pipeline. Measurements should span different time intervals (e.g., minutes, weeks, months) to evaluate stability [5]. |
| Multi-Criterion Validation Framework | A structured approach that evaluates pipelines based on multiple criteria (reliability, sensitivity, generalizability) rather than a single metric, ensuring robust performance [5]. |
| Parcellation Evaluation Metrics Suite | A set of quantitative measures, including region homogeneity and region separation, used to judge the effectiveness of a brain parcellation in the absence of ground truth [87]. |
| Containerized Computing Environment | A standardized software environment (e.g., using Docker/NeuroDocker) that ensures computational reproducibility by eliminating variability from software versions and operating systems [7]. |
| HCP Multi-Pipeline Dataset | A derived dataset providing statistic maps from 24 different fMRI pipelines run on 1,080 participants. It serves as a benchmark for studying analytical variability [7]. |
| Portrait Divergence (PDiv) Metric | An information-theoretic tool used to quantify the dissimilarity between whole-network topologies, crucial for evaluating test-retest reliability [5]. |
The integration of neuroimaging into drug development, particularly for neurological disorders, requires rigorous reliability assessment to ensure that biomarkers used for target engagement and patient stratification are robust and reproducible. High-resolution patient stratification, driven by combinatorial analytics and artificial intelligence (AI), enables the identification of patient subgroups most likely to respond to a therapy by mapping disease signatures comprising genetic, molecular, and imaging biomarkers [89]. This approach is critical for overcoming patient heterogeneity and reducing late-stage clinical trial failures.
However, the pathway from data acquisition to clinical decision-making—the neuroimaging pipeline—is susceptible to multiple sources of variability. The "Cycle of Quality" in magnetic resonance imaging (MRI) encompasses a dynamic process spanning scanner operation, data integrity, harmonization across sites, algorithmic robustness, and research dissemination [90]. Ensuring reliability at each stage is paramount for generating translatable evidence in drug development programs. This technical support center provides troubleshooting guides and FAQs to help researchers address specific challenges in applying reliability metrics to target engagement and patient stratification within their neuroimaging pipelines.
Frequently Asked Questions (FAQs) and Troubleshooting Guides
Biomarker and Patient Stratification
Q1: Our patient stratification model, based on a neuroimaging biomarker, is failing to predict treatment response in a new patient cohort. What could be the cause?
This is often a problem of poor generalizability and can be broken down into several potential failure points and solutions:
- Potential Cause 1: Technical Variability in Imaging Data. Differences in MRI scanners, acquisition protocols, or reconstruction software between your original training cohort and the new cohort can introduce technical confounds that overwhelm biological signals [90].
Solution: Implement a harmonization framework.
- Prospective Harmonization: Use vendor-neutral sequence definitions (e.g., via
Pulseq) and open-source reconstruction pipelines (e.g.,Gadgetron) to standardize data acquisition across sites [90]. - Retrospective Harmonization: Apply statistical harmonization methods, such as
ComBat, to remove site-specific effects from the extracted imaging features. Validate the success of harmonization using site-predictability metrics and traveling-heads studies [90].
- Prospective Harmonization: Use vendor-neutral sequence definitions (e.g., via
Potential Cause 2: Inadequate Biomarker Validation. The biomarker may not have been sufficiently validated for its intended purpose (e.g., predictive vs. prognostic) or across diverse patient populations [91].
Solution: Revisit the biomarker validation process.
- Analytical Validation: Ensure the biomarker assay is reliable, sensitive, and specific.
- Clinical Validation: Confirm that the biomarker consistently predicts the clinical outcome of interest in independent cohorts. This requires a clear definition of the biomarker's clinical context of use [91].
Potential Cause 3: Underpowered Subgroup Identification. The initial patient stratification may have been based on underpowered analyses that did not capture the true biological heterogeneity of the disease [89].
- Solution: Utilize combinatorial analytics. Instead of relying on single biomarkers, use AI methods to identify disease signatures—combinations of multiple genetic, clinical, and imaging features—that more robustly define patient subgroups and their associated disease mechanisms [89].
Q2: How can we reliably stratify patients for a clinical trial when our neuroimaging data comes from a small cohort?
Small cohorts are common in rare neurological diseases. The key is to maximize information extraction and avoid overfitting.
- Challenge: Limited statistical power and high risk of model overfitting [92].
- Solutions:
- Prioritize Pipeline Simplicity: Extensive tuning of machine learning pipelines (e.g., complex feature selection, hyperparameter optimization) offers only marginal gains on small datasets. Focus on robust, simple models [92].
- Subject-Wise Feature Normalization: This preprocessing step has been shown to improve classification outcomes in small-sample settings by reducing inter-subject variability [92].
- Data Enrichment: Progressively expand the dataset by integrating additional multimodal data (e.g., combining structural MRI with diffusion tensor imaging or sodium imaging) to capture complementary information and improve model stability [92].
- Leverage Alternative Stratification Tools: If tissue samples are available, consider label-free platforms like
PIMSthat analyze patient-derived cells or tissues to identify biological responses to drug candidates, enabling precise patient stratification independent of cohort size [93].
Target Engagement and Assay Performance
Q3: Our target engagement assay shows an unacceptable level of noise, making it difficult to interpret the results. How can we improve its robustness?
Assay noise compromises the ability to make reliable decisions about a drug's interaction with its target.
- First, calculate the Z'-factor: This is a key metric to assess the robustness and suitability of an assay for screening. It incorporates both the assay window and the data variability [94].
- Formula:
Z' = 1 - [ (3 * SD_positive_control + 3 * SD_negative_control) / |Mean_positive_control - Mean_negative_control| ] - Interpretation: A Z'-factor > 0.5 is considered suitable for screening. A large assay window is useless if the noise (standard deviation) is also large [94].
- Formula:
- Troubleshooting Steps:
- Review Instrument Setup: For TR-FRET assays, a complete lack of an assay window is often due to incorrect emission filters on the microplate reader. Consult instrument setup guides for the correct configuration [94].
- Optimize Washing Procedures: In ELISA-based assays, high background noise can result from incomplete washing of microtiter wells, leading to carryover of unbound reagent. Follow recommended washing techniques precisely and avoid over-washing or soaking [95].
- Check for Reagent Contamination: Sensitive assays can be compromised by airborne contamination or contaminated reagents. Clean work surfaces, use aerosol barrier pipette tips, and avoid using automated plate washers that have been exposed to concentrated analytes [95].
Q4: The EC50/IC50 values from our target engagement assays are inconsistent between replicate experiments. What are the common sources of this variability?
The primary reason for differences in EC50/IC50 values between labs or experiments is often related to stock solution preparation [94].
- Root Cause: Variability in the preparation, storage, or dilution of compound stock solutions.
- Solutions:
- Standardize Stock Solutions: Ensure consistent preparation of stock solutions, typically at 1 mM, across all experiments. Use calibrated pipettes and high-quality source compounds.
- Use Ratiometric Data Analysis: For TR-FRET assays, always use the emission ratio (acceptor signal/donor signal) rather than raw relative fluorescence units (RFUs). This ratio accounts for minor variances in pipetting and reagent lot-to-lot variability, providing more consistent results [94].
- Validate Curve Fitting: Avoid using linear regression for inherently non-linear immunoassay data. Use interpolation methods that are robust and accurate for immunoassays, such as point-to-point, cubic spline, or 4-parameter logistic curves [95]. Verify the fit by "back-fitting" the standard values as unknowns.
Data Analysis and Validation
Q5: Our quantitative MRI (qMRI) biomarker shows significant variability across different clinical trial sites, threatening our target engagement study. How can we mitigate this?
qMRI is notoriously sensitive to confounding factors across scanners and sites.
- Problem: qMRI measurements are confounded by scanner-specific instabilities, sequence parameters, and physiological noise [90].
- Mitigation Strategy:
- Understand and Mitigate Confounds: Systematically identify sources of variance (e.g.,
B1+field inhomogeneity, gradient nonlinearities) and integrate correction steps into a standardized processing pipeline [90]. - Structured Validation: Adopt a framework for assessing qMRI reliability.
- Technical Performance: Assess bias, noise, and repeatability using phantoms and test-retest studies.
- Clinical Performance: Ensure the quantitative values are interpretable and traceable to validated standards. Provide normative ranges for context [90].
- Implement a Quality Framework for AI: If using AI to analyze qMRI data, demand the same rigor as for traditional biomarkers. Models must be evaluated for reproducibility, interpretability, and generalizability across diverse, real-world datasets [90].
- Understand and Mitigate Confounds: Systematically identify sources of variance (e.g.,
The Scientist's Toolkit: Essential Reagents and Platforms
The table below details key reagents, technologies, and platforms essential for experiments in target engagement and patient stratification.
Table 1: Key Research Reagent Solutions and Their Functions
| Item/Platform | Primary Function | Key Application in Drug Development |
|---|---|---|
| PIMS Platform [93] | Label-free analysis of patient-derived cells/tissues to identify biological responses to drugs. | Precise patient stratification and biomarker discovery by identifying patient subgroups most likely to respond to a treatment. |
| Combinatorial Analytics [89] | AI-driven method to identify disease-associated combinations of features (disease signatures). | High-resolution patient stratification by discovering biomarkers that define patient subgroups with shared disease biology. |
| TR-FRET Assays [94] | Biochemical assay technology to study molecular interactions (e.g., kinase binding). | Measuring target engagement and compound potency (EC50/IC50) in vitro. |
| Z'-LYTE Assay [94] | Fluorescent biochemical assay for measuring kinase activity and inhibition. | Screening and profiling compounds for their ability to modulate kinase target activity. |
| Next-Generation Sequencing (NGS) [91] | High-throughput technology for sequencing millions of DNA fragments in parallel. | Identifying genetic mutations and alterations that serve as diagnostic, prognostic, or predictive biomarkers. |
| Liquid Biopsies [91] | Non-invasive method to analyze biomarkers (e.g., circulating tumor DNA) from blood. | Monitoring disease progression and treatment response dynamically, particularly in oncology. |
Experimental Protocols and Workflows
Protocol for Validating a Patient Stratification Biomarker
This protocol outlines the key steps for validating a neuroimaging-based biomarker to stratify patients in a clinical trial.
- Define Context of Use: Precisely specify the biomarker's purpose (e.g., "to identify patients with early Alzheimer's disease who are likely to show a 30% slowing of cognitive decline on drug X").
- Assay Analytical Validation: Establish the technical performance of the biomarker measurement.
- Repeatability: Assess intra-scanner, intra-protocol variability using test-retest studies.
- Reproducibility: Assess inter-scanner, inter-site variability using a harmonization protocol [90].
- Calculate intra-class correlation coefficients (ICC) to quantify reliability.
- Clinical Validation: Establish the biomarker's link to clinical outcomes.
- Using a dedicated cohort, test the hypothesis that the stratified patient subgroup shows a statistically significant and clinically meaningful differential response to the treatment compared to the non-stratified population.
- Prospective Blinded Validation: Lock the biomarker signature and analysis pipeline. Then, apply it to a new, independent prospective cohort in a blinded manner to confirm its predictive value [89] [91].
Workflow for a Reliability-Focused Neuroimaging Analysis Pipeline
The following diagram illustrates a robust workflow for analyzing neuroimaging data that incorporates critical reliability checkpoints, from acquisition to patient stratification.
Diagram 1: Reliability-focused neuroimaging pipeline with quality checkpoints.
Data Presentation: Key Reliability Metrics and Specifications
Assay Performance and Quality Metrics
The following table summarizes key quantitative metrics used to evaluate the reliability of assays and biomarkers in drug development.
Table 2: Key Reliability Metrics for Experimental Data Quality
| Metric | Definition | Interpretation & Benchmark |
|---|---|---|
| Z'-factor [94] | A statistical measure of assay robustness that incorporates both the signal dynamic range and the data variation. | > 0.5: Excellent assay suitable for screening.0.5 to 0: A "gray area," may be usable but not robust.< 0: Assay window is too small and/or too noisy. |
| Intra-class Correlation Coefficient (ICC) | Measures reliability or agreement between repeated measurements (e.g., test-retest, inter-scanner). | > 0.9: Excellent reliability.0.75 - 0.9: Good reliability.< 0.75: Poor to moderate reliability; may not be suitable for patient-level decisions. |
| Assay Window [94] | The fold-change between the maximum and minimum signals in a dose-response or binding curve. | A large window is beneficial, but the Z'-factor is a more comprehensive metric. A 10-fold window with 5% standard error yields a Z'-factor of ~0.82 [94]. |
| Spike & Recovery [95] | A measure of accuracy where a known amount of analyte is added ("spiked") into a sample and the percentage recovery is calculated. | 95% - 105%: Typically considered acceptable, indicating minimal matrix interference. |
| Dilutional Linearity [95] | The ability to obtain consistent results when a sample is diluted, confirming the absence of "Hook Effect" or matrix interference. | Recovered concentrations should be proportional to the dilution factor. |
Biomarker Validation Criteria
The following table outlines the key criteria for validating different types of biomarkers used in patient stratification.
Table 3: Biomarker Validation Criteria and Purpose
| Biomarker Type | Primary Purpose | Key Validation Criteria |
|---|---|---|
| Diagnostic [91] | To detect or confirm the presence of a disease. | High sensitivity and specificity compared to a clinical gold standard. |
| Prognostic [91] | To predict the natural course of a disease, regardless of therapy. | Significant association with a clinical outcome (e.g., survival, disease progression) in an untreated/standard-care population. |
| Predictive [91] | To identify patients more likely to respond to a specific therapy. | Significant interaction between the biomarker status and the treatment effect on a clinical endpoint in a randomized controlled trial. |
| Pharmacodynamic (PD) [91] | To measure a biological response to a therapeutic intervention. | A dose- and time-dependent change in the biomarker that aligns with the drug's mechanism of action. |
Conclusion
The pursuit of reliable neuroimaging pipelines is fundamental to advancing both neuroscience research and clinical drug development. The evidence clearly shows that methodological choices at the preprocessing stage significantly impact the reproducibility of scientific findings, underscoring the necessity for standardized, transparent workflows. The emergence of deep learning-accelerated pipelines like DeepPrep and FastSurfer demonstrates a path forward, offering not only dramatic computational efficiency gains but also improved robustness for handling the data diversity encountered in real-world clinical populations. Furthermore, rigorous validation frameworks such as ICED provide the necessary tools to quantitatively decompose and understand sources of measurement error. For the future, the integration of these reliable, high-throughput pipelines with artificial intelligence and predictive modeling holds immense promise for de-risking drug development—enabling better target engagement assessment, precise patient stratification, and more efficient clinical trials. A continued commitment to standardization, open-source tool development, and community-wide adoption of reliability assessment practices will be crucial for building a more reproducible and impactful neuroimaging science.
References
- 1. Replication and generalization in applied neuroimaging [https://www.sciencedirect.com/science/article/pii/S1053811919306299]
- 2. Replicability and generalizability in population psychiatric ... [https://www.nature.com/articles/s41386-024-01960-w]
- 3. Replicability and generalizability in population psychiatric ... [https://pubmed.ncbi.nlm.nih.gov/39215207/]
- 4. Towards building a trustworthy pipeline integrating ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10998337/]
- 5. Systematic evaluation of fMRI data-processing pipelines for ... [https://www.nature.com/articles/s41467-024-48781-5]
- 6. Looking for some troubleshooting suggestions for fMRIPrep [https://neurostars.org/t/looking-for-some-troubleshooting-suggestions-for-fmriprep/17311]
- 7. a derived dataset to investigate analytical variability in fMRI [https://www.nature.com/articles/s41597-025-05247-7]
- 8. Open-source platforms to investigate analytical flexibility in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12330840/]
- 9. Which software packages did researchers use to meta ... [https://www.frontiersin.org/journals/human-neuroscience/articles/10.3389/fnhum.2025.1580808/full]
- 10. ENIGMA's advanced guide for parcellation error ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12335952/]
- 11. Quality control strategies for brain MRI segmentation and ... [https://www.sciencedirect.com/science/article/pii/S1053811921004511]
- 12. Academic Software Demos [https://biomedicalimaging.org/2025/academic-software-demos/]
- 13. fNIRS reproducibility varies with data quality, analysis ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12322209/]
- 14. Understanding the impact of preprocessing pipelines on ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7821710/]
- 15. A large-scale comparison of cortical thickness and volume ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5187496/]
- 16. Troubleshooting your output [https://surfer.nmr.mgh.harvard.edu/fswiki/FsTutorial/TroubleshootingData]
- 17. PhiPipe: A multi‐modal MRI data processing pipeline with ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9980895/]
- 18. FAQ, Tips, and Tricks — fmriprep version documentation [https://fmriprep-test.readthedocs.io/en/stable/faq_tips_tricks.html]
- 19. Standardized Preprocessing in Neuroimaging: Enhancing ... [https://link.springer.com/protocol/10.1007/978-1-0716-4260-3_8]
- 20. The Autism Brain Imaging Data Exchange - PubMed Central [https://pmc.ncbi.nlm.nih.gov/articles/PMC4162310/]
- 21. Functional connectivity-based prediction of Autism on site ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8696194/]
- 22. Identification of critical brain regions for autism diagnosis ... [https://pubmed.ncbi.nlm.nih.gov/41181843/]
- 23. Deriving and validating biomarkers associated with autism ... [https://www.nature.com/articles/s41598-019-45465-9]
- 24. A novel pipeline leveraging surface-based features of small ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9632410/]
- 25. Model selection to achieve reproducible associations ... [https://www.nature.com/articles/s41598-024-76659-5]
- 26. ICA-Based Resting-State Networks Obtained on Large ... [https://www.mdpi.com/2306-5729/10/7/109]
- 27. fMRI data of mixed gambles from the Neuroimaging ... [https://www.nature.com/articles/s41597-019-0113-7]
- 28. Variability in the analysis of a single neuroimaging dataset ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7771346/]
- 29. NARPS Project: the robustness of the scientific method put ... [https://www.inria.fr/en/narps-project-robustness-scientific-method-put-test]
- 30. Why experimental variation in neuroimaging should be ... [https://www.nature.com/articles/s41467-024-53743-y]
- 31. Highlight results, don't hide them: Enhance interpretation ... [https://www.sciencedirect.com/science/article/pii/S1053811923002896]
- 32. A Unified Framework for Reliability Analysis in ... [https://researchprofiles.ku.dk/en/publications/a-unified-framework-for-reliability-analysis-in-neuroimaging-with-2/]
- 33. FastSurfer - A fast and accurate deep learning based ... [https://www.sciencedirect.com/science/article/pii/S1053811920304985]
- 34. Usage Notes (Local) - DeepPrep documentation [https://deepprep.readthedocs.io/en/latest/usage_local.html]
- 35. Deep-MI/FastSurfer: PyTorch implementation of ... [https://github.com/Deep-MI/FastSurfer]
- 36. DeepPrep: an accelerated, scalable and robust pipeline for ... [https://www.nature.com/articles/s41592-025-02599-1]
- 37. FastSurfer - A fast and accurate deep learning based ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7898243/]
- 38. FastSurfer [https://deep-mi.org/research/fastsurfer/]
- 39. Fast cortical surface reconstruction from MRI using deep ... [https://braininformatics.springeropen.com/articles/10.1186/s40708-022-00155-7]
- 40. Welcome to DeepPrep's documentation! — DeepPrep ... [https://deepprep.readthedocs.io/]
- 41. Comprehensive Benchmarking of Machine Learning ... [https://arxiv.org/abs/2503.08870]
- 42. Research Analysis Platform - UKB-RAP [https://www.ukbiobank.ac.uk/use-our-data/research-analysis-platform/]
- 43. Robust Ensemble of Two Different Multimodal Approaches ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11522214/]
- 44. Evaluating machine learning pipelines for multimodal ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12202540/]
- 45. The Brain Imaging Data Structure: BIDS [https://bids.neuroimaging.io/index.html]
- 46. NeuroImaging PREProcessing toolS (NiPreps) [https://www.nipreps.org/nipreps-book/nipreps/nipreps.html]
- 47. sMRIPrep: Structural MRI PREProcessing pipeline [https://www.nipreps.org/smriprep/]
- 48. What's new? - sdcflows 0+unknown documentation [https://www.nipreps.org/sdcflows/2.14/changes.html]
- 49. A reproducible and generalizable software workflow ... - PubMed [https://pubmed.ncbi.nlm.nih.gov/37645999/]
- 50. NiPreps Hack 2025 [https://hackmd.io/@NiPreps-techmon/NiHack2025]
- 51. PETPrep: A Robust Preprocessing Pipeline for PET Data [https://github.com/nipreps/petprep]
- 52. Neurodesk: an accessible, flexible and portable data analysis ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11180540/]
- 53. What is Workflow Portability? A Breakdown of HPC ... - Simr Blog [https://blog.simr.com/what-is-workflow-portability-part-1-hpc-architecture-and-components]
- 54. Democratizing open neuroimaging: Neurodesk's approach ... [https://apertureneuro.org/article/144107-democratizing-open-neuroimaging-neurodesk-s-approach-to-open-data-accessibility-and-utilization]
- 55. Neuroimaging article reexecution and reproduction ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11298386/]
- 56. fNIRS reproducibility varies with data quality, analysis ... [https://www.nature.com/articles/s42003-025-08412-1]
- 57. Fast cortical surface reconstruction from MRI using deep ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8907118/]
- 58. DeepPrep: an accelerated, scalable and robust pipeline for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11903312/]
- 59. A Standardized Protocol for Efficient and Reliable Quality ... [https://www.frontiersin.org/journals/neuroinformatics/articles/10.3389/fninf.2020.00007/full]
- 60. Inter-rater reliability of functional MRI data quality control ... [https://www.frontiersin.org/journals/neuroscience/articles/10.3389/fnins.2023.1070413/full]
- 61. Optimizing fMRI preprocessing pipelines for block-design ... [https://pubmed.ncbi.nlm.nih.gov/28216431/]
- 62. Optimizing fMRI preprocessing pipelines for block-design ... [https://www.sciencedirect.com/science/article/abs/pii/S1053811917301398]
- 63. Best Practices in Structural Neuroimaging of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9090677/]
- 64. Integrated decision support system for optimizing time and ... [https://www.nature.com/articles/s41598-025-02837-8]
- 65. AWS re:Invent 2025: Your Complete Guide to High ... [https://aws.amazon.com/blogs/hpc/aws-reinvent-2025-your-complete-guide-to-high-performance-computing-sessions/]
- 66. Supercomputing 2025 Shines Spotlight On AI, HPC ... [https://www.crn.com/news/computing/2025/supercomputing-2025-shines-spotlight-on-ai-hpc-targeted-performance]
- 67. Improving GPU Utilization: Strategies and Best Practices [https://www.mirantis.com/blog/improving-gpu-utilization-strategies-and-best-practices/]
- 68. CUDA C++ Best Practices Guide [https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/]
- 69. Kubernetes GPU Resource Management Best Practices [https://www.perfectscale.io/blog/kubernetes-gpu]
- 70. Kubernetes GPU Resource Management Best Practices [https://collabnix.com/kubernetes-gpu-resource-management-best-practices-complete-technical-guide-for-2025/]
- 71. GPU Benchmarks Hierarchy 2025 - Graphics Card Rankings [https://www.tomshardware.com/reviews/gpu-hierarchy,4388.html]
- 72. CPU Benchmarks and Hierarchy 2025: CPU Rankings [https://www.tomshardware.com/reviews/cpu-hierarchy,4312.html]
- 73. Best graphics card in 2025 [https://www.club386.com/best-graphics-card/]
- 74. Best graphics cards in 2025: I've tested pretty much every ... [https://www.pcgamer.com/the-best-graphics-cards/]
- 75. Assessing reliability in neuroimaging research through intra ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6044907/]
- 76. Measuring fMRI reliability with the intra-class correlation ... [https://www.sciencedirect.com/science/article/abs/pii/S105381190801327X]
- 77. Coefficient of variation [https://en.wikipedia.org/wiki/Coefficient_of_variation]
- 78. 3.2.1: Coefficient of Variation [https://stats.libretexts.org/Courses/Las_Positas_College/Math_40%3A_Statistics_and_Probability/03%3A_Data_Description/3.02%3A_Measures_of_Variation/3.2.01%3A_Coefficient_of_Variation]
- 79. Intraclass correlation: Improved modeling approaches and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5807222/]
- 80. Intraclass correlation [https://en.wikipedia.org/wiki/Intraclass_correlation]
- 81. A Guideline of Selecting and Reporting Intraclass ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4913118/]
- 82. Test-retest reliability of multi-parametric maps (MPM) ... [https://www.sciencedirect.com/science/article/pii/S1053811922003731]
- 83. Assessing reliability in neuroimaging research through ... [https://elifesciences.org/articles/35718]
- 84. Effects of measurement errors on relationships between ... [https://www.nature.com/articles/s41598-025-13105-0]
- 85. fMRIPrep Lifespan: Extending A Robust Pipeline for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12132292/]
- 86. What's new — fmriprep version documentation [https://fmriprep.org/en/25.1.0/changes.html]
- 87. Evaluation of functional MRI-based human brain parcellation [https://pmc.ncbi.nlm.nih.gov/articles/PMC9291407/]
- 88. A Tutorial Review of Functional Connectivity Analysis ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4705224/]
- 89. Systematic indication extension for drugs using patient ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9214305/]
- 90. ESMRMB 2025 focus topic: cycle of quality—from concept to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12255560/]
- 91. Biomarker Analysis in Drug Development [https://blog.crownbio.com/biomarker-analysis-drug-development-precision-medicine]
- 92. Evaluating machine learning pipelines for multimodal ... [https://www.frontiersin.org/journals/neuroinformatics/articles/10.3389/fninf.2025.1568116/full]
- 93. Patient Cohort Stratification [https://www.inoviem.com/patient-stratification/]
- 94. Drug Discovery Assays Support—Troubleshooting [https://www.thermofisher.com/us/en/home/technical-resources/technical-reference-library/drug-discovery-development-support-center/drug-discovery-assays-support/drug-discovery-assays-support-troubleshooting.html]
- 95. Troubleshooting & FAQs [https://www.cygnustechnologies.com/resources/guidelines?srsltid=AfmBOoqkPOGpTms7molVg8ug_l8gVx839n9RZd0a-1YlxIa9WnCyoSKL]